

简介
QwQ-32B 是阿里云开源的 320 亿参数推理模型,通过大规模强化学习,千问 QwQ-32B 在数学、代码及通用能力上实现质的飞跃,整体性能比肩DeepSeek-R1。QwQ-32B 具备强大的数学、代码和通用推理能力,性能比肩全球顶尖开源模型。它支持消费级显卡部署,降低硬件门槛,同时集成智能体能力,可灵活调整推理过程。采用 Apache 2.0 协议开源,用户可免费下载、商用和定制化开发,推动 AI 技术的广泛应用。
主要特点
-高性能推理能力:QwQ-32B 在多项权威基准测试中表现出色,数学和代码能力与当前最强开源模型 DeepSeek-R1 相当,显著优于其他同类模型(如 OpenAI-o1-mini)。
-低资源消耗:QwQ-32B 优化了模型的资源需求,能够在消费级显卡上实现本地部署,适合对硬件资源有限制的应用场景,如个人开发者、中小企业等。
-集成智能体能力:模型集成了智能体(Agent)能力,能够进行批判性思考,并根据环境反馈调整推理过程,使其在复杂任务中表现出更高的灵活性和适应性。
-开源与免费商用:QwQ-32B 采用宽松的 Apache 2.0 协议开源,用户可以免费下载、部署和商用,降低了使用门槛,推动了 AI 技术的普及。
调用方式
-本地部署:用户可以通过魔搭社区或 HuggingFace 下载模型进行本地部署。
-云端调用:用户可以通过阿里云 PAI 平台调用模型 API,或者使用容器服务 ACK 结合 GPU 算力进行高效推理。
QwQ-32B的模型效果
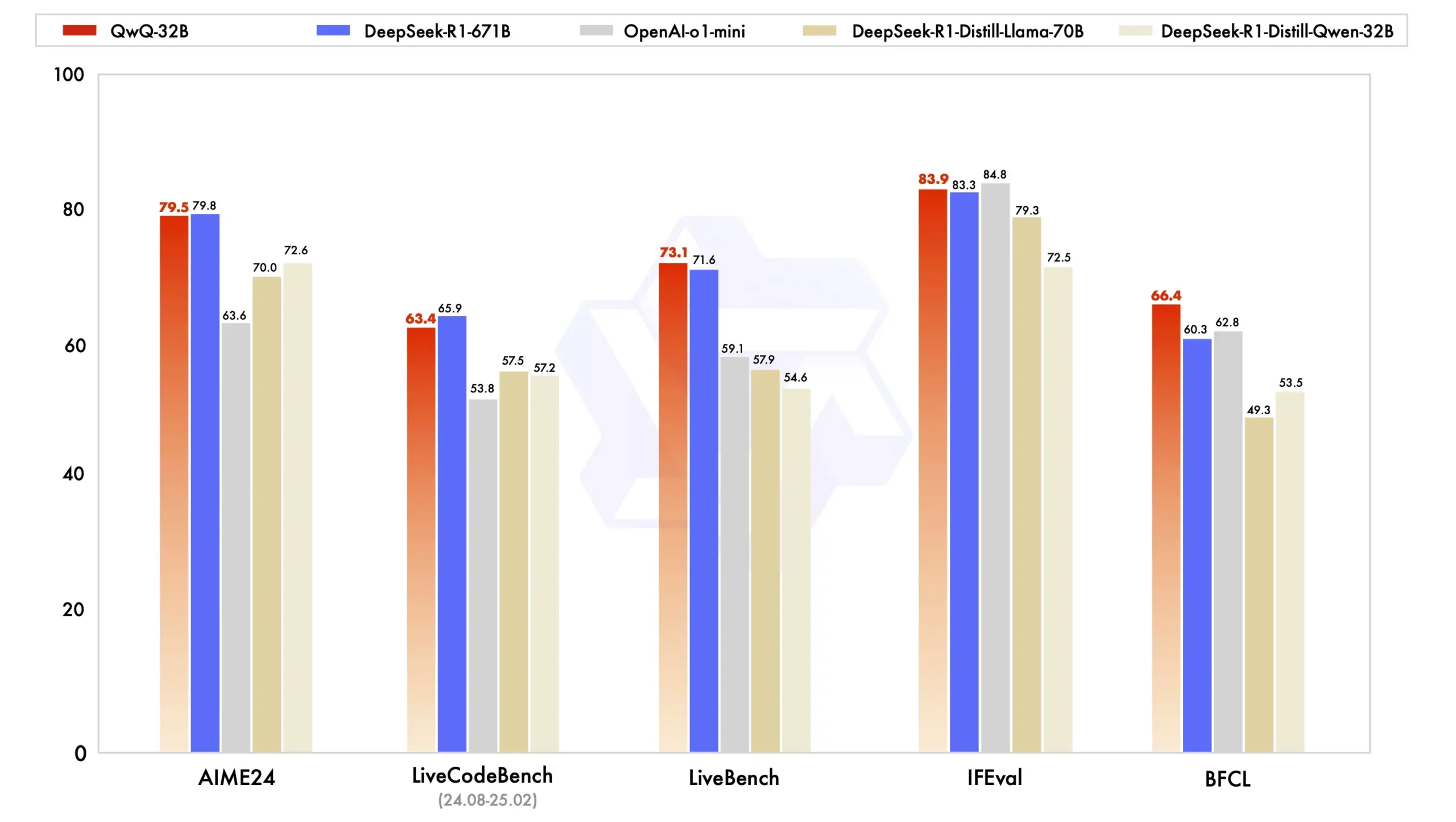
QwQ-32B 在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。以下结果展示了 QwQ-32B 与其他领先模型的性能对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始的 DeepSeek-R1。
数学能力
在 AIME24 数学评测集上,QwQ-32B 的表现与 DeepSeek-R1 相当,远超 OpenAI-o1-mini 和同尺寸的 R1 蒸馏模型。
编程能力
在 LiveCodeBench 编程能力评测中,QwQ-32B 同样与 DeepSeek-R1 表现相当,展现出强大的代码生成和理解能力。
通用能力
- 在 Meta 首席科学家杨立昆领衔的 LiveBench(“最难 LLMs 评测榜”)中,QwQ-32B 的得分超越了 DeepSeek-R1。
- 在谷歌提出的 IFEval 指令遵循能力评测中,QwQ-32B 的成绩也优于 DeepSeek-R1。
- 在加州大学伯克利分校提出的 BFCL 测试中,QwQ-32B 同样超越了 DeepSeek-R1。
成本与效率QwQ-32B 的运行成本显著低于 DeepSeek-R1 和其他同类模型。例如,在 LiveBench 评分中,QwQ-32B 的评分约为 72.5 分,成本仅为 $0.25,而 DeepSeek-R1 的评分约为 70 分,成本约为 $2.50。
如何使用
项目官网
https://qwenlm.github.io/zh/blog/qwq-32b/
在线免费体验
https://chat.qwen.ai/?models=Qwen2.5-Plus
开源地址
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/%e5%8d%83%e9%97%aeqwq-32b.html -APPMARK
百川大模型是百川智能 推出的大模型产品,融合了意图理解、信息检索以及强化学习技术,结合有监督微调与人类意图对齐,在知识问答、文本创作领域表现突出。