


摘要:Arena 是一个把前沿模型体验、匿名对战投票、公开排行榜与开放研究数据整合到一起的 AI 平台。它的价值不只在于“能和模型聊天”,而在于把真实用户使用、模型横向比较、公开排名、方法论透明和研究数据开放放到同一产品里。对于 AI 导航站读者来说,Arena 值得单独收录,因为它既是多模型使用入口,也是观察真实世界模型表现变化的重要窗口。
这是什么产品
Arena 官网首页把自己放在一个很明确的位置:它不是只提供单一模型服务的聊天产品,也不是单纯展示静态榜单的数据看板,而是一个“既能直接体验前沿模型,又能用社区投票推动公开评测”的平台。首页最醒目的入口就是 Battle Mode,对应的标语是 “Experience the frontier”。这意味着官方希望用户在真实任务里和前沿模型交互,而不是只围观别人做出的 benchmark 结论。
从 About Us 页面可以看得更清楚。官方写明 Arena 由 UC Berkeley 的研究者创建,前身是 LMArena,定位是一个 community-powered platform,用于理解 AI 在真实世界中的表现。页面还强调,数以千万计的 builders、researchers 和 creative professionals 会来到这里使用 frontier models 并给出反馈,这些反馈会进一步塑造公开排行榜。这种表述说明 Arena 的核心不是“卖某个自研模型”,而是围绕多模型使用与评测建立一个开放平台。
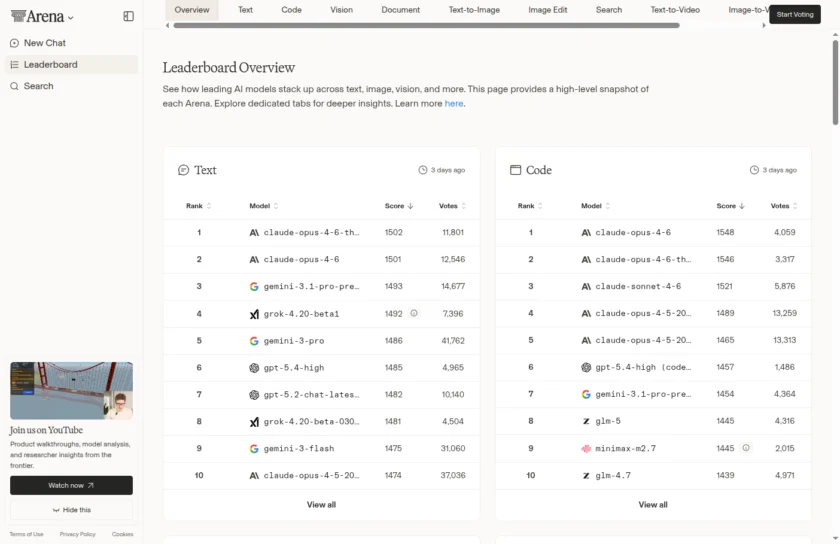
进一步看其站点结构,Arena 不只覆盖文本聊天。排行榜页已经扩展到 Text、Code、Vision、Document、Search、Text-to-Image、Image Edit、Text-to-Video、Image-to-Video 和 Video Edit 等多个赛道;底部 use cases 还直接列出了 Chat with AI、Build Apps & Websites、Write & Edit Text、Search the Web、Generate Images、Generate Videos、Choose any model、Compare Models Side by Side。这说明它更像是一个多模型、多任务、多模态的统一入口,因此我把它归到 AI模型平台 > 一站式管理与应用,而不是只归进“AI聊天”或“AI搜索”这样的单点分类。
核心功能与使用体验
Arena 的核心体验可以拆成四层。第一层是直接使用模型。你可以像在普通 AI 聊天产品里那样输入 prompt、附加文件,并根据任务选择不同模式,例如搜索、图像、代码或视频。第二层是 Battle Mode,也就是匿名模型对战:系统会给你两组匿名回答,你只根据输出结果判断哪一个更好,这一步决定了它和普通多模型聚合器的本质差异,因为这里的使用行为会回流成评测数据。
第三层是公开排行榜。Arena 并不是把评测结果藏在后台,而是直接把不同赛道的榜单公开出来,用户能看到文本、代码、视觉、搜索乃至图像与视频相关任务中各模型的分数、票数和近期变化。对开发者、研究者和重度用户来说,这个功能很有价值,因为它让“今天到底该优先试哪个模型”不再只是看厂商宣传,而是能直接看公开对比结果。尤其当一个模型在文本强、另一个模型在代码或搜索强时,Arena 给的是一个更贴近日常使用的横向判断面板。
第四层是研究与开放数据。How It Works 和 FAQ 页面反复强调,用户的投票会进入公开排行榜,而平台也会把部分匿名化数据开放给研究社区;同时 About 与 How It Works 页面还给出了 Hugging Face 数据集、ICML/NeurIPS/ICLR 等研究论文链接。换句话说,Arena 不是把“投票”当成简单互动组件,而是把它变成真实研究基础设施的一部分。这也是它与很多只提供“模型切换器”的产品完全不同的地方。
从实际使用感受推断,Arena 最适合那些不想被某一家模型厂商绑定的人。你可以在同一个平台上比较不同模型的即时回答,也可以在投票后看到身份揭晓,继续同一会话或重新开始。FAQ 还说明在匿名状态下产生的投票才会计入官方排名,这让它的 Battle Mode 更接近“真实世界里的盲测”。这种设计把产品体验、社区反馈和模型评估绑成了一个闭环。
如何开始使用
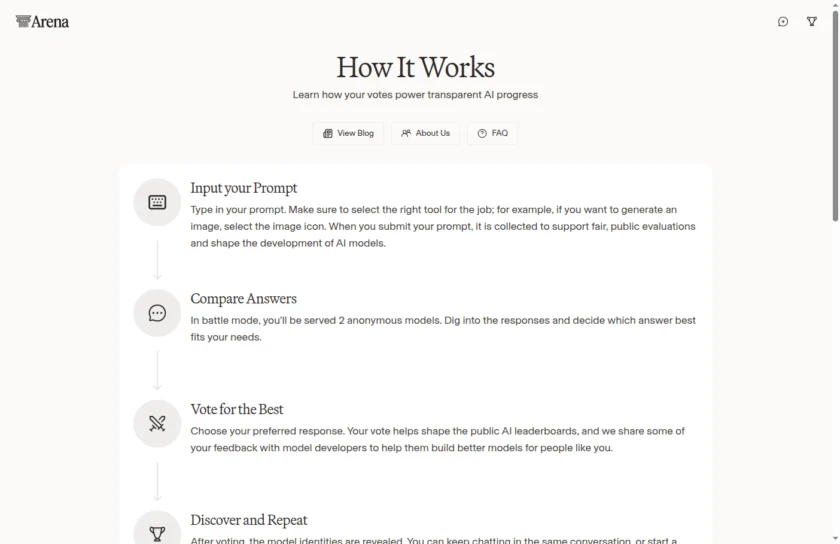
Arena 的上手路径很直接。首页就是入口,打开官网后即可看到输入框与模式切换按钮。How It Works 页面给出的第一步是输入 prompt,并根据任务选择合适工具;例如如果你想生成图片,就选图像入口。提交之后,系统会把请求用于支持公平公开的评测,并在 Battle Mode 中给出两组匿名答案。第二步是 Compare Answers,也就是认真对比两个模型的输出。第三步是 Vote for the Best,你根据自身需求选择更优答案;官方明确写到,这个投票会帮助塑造公开排行榜,并且部分反馈会共享给模型开发者以改进产品。第四步则是 Discover and Repeat,投票之后模型身份会揭晓,你可以继续同一对话,也可以重新开始。
FAQ 页补充了几个关键规则。首先,只有在匿名状态下做出的投票才会计入官方排名;模型名称会在投票完成后才揭晓,以减少品牌偏见。其次,你可以提交任意多的 prompt 和投票,这意味着 Arena 不是一次性的“试玩页”,而是希望用户持续参与评测。再次,官方说明有些模型会以代号或别名出现,因为平台会和开源及商业模型提供方合作,让社区提前测试仍在开发中的前沿模型。这一点对想抢先感知模型趋势的人很有吸引力。
如果你不是来参与匿名对战,而是只想直接使用特定模型,Arena 也预留了 Direct Mode 和 Side by Side 等路径。How It Works 与页脚 use cases 页面都能看到 Chat with AI、Build Apps & Websites、Search the Web、Generate Images、Choose any model、Compare Models Side by Side 等入口。这意味着它既可以作为普通使用平台,也可以作为比较平台;只是相比单纯聊天产品,它多了一套更完整的评测逻辑。
价格、开源与部署方式
从当前官方公开页面来看,Arena 主要表现为在线托管平台,而不是一个面向个人部署的开源应用。官网、How It Works、About 和 FAQ 页面都围绕在线交互、公开排行榜、研究数据与评测服务展开,没有把它描述成可本地安装的桌面软件,也没有给出自托管部署路线。更合理的理解是:Arena 的主产品形态是 Web 平台,用户直接在官方站点中体验和比较模型。
价格方面,官网公开页没有像典型 SaaS 那样提供标准订阅价目表。FAQ 中倒是明确回答了“如何维持财务运转”:官方表示他们向企业、模型实验室和开发者提供基于真实世界人类反馈的 AI Evaluations 服务,以此支持平台运作。这说明 Arena 至少存在企业级评测服务的商业化路径,但普通用户前台体验的收费结构并没有在当前公开页里详细写明。因此在导航站里不宜编造“免费/付费/套餐档位”结论,更稳妥的写法是:普通使用与排行榜浏览可以直接访问,企业评测服务需要与团队联系确认。
开源与开放数据方面,Arena 的情况很有意思:平台本身并未在这些页面中被表述为一个完整开源应用,但其研究导向非常强,官方明确写到已经 open-sourced the largest repository of organic human preferences on generative models in the world,并提供 Hugging Face 数据集入口及多篇论文。也就是说,它不是“软件层完全开源”的典型项目,却在数据与研究层保持了很强的开放性。
适合哪些人和场景
Arena 最适合三类人。第一类是重度 AI 用户,他们不满足于只使用一个固定模型,而是想持续比较不同模型在文本、代码、搜索、图像或视频任务上的表现。对于这类用户,Arena 的价值在于它同时提供使用入口和参考坐标:你既能直接试,也能马上回头看榜单位置。第二类是开发者和研究者,他们需要基于真实人类偏好理解模型优劣,而不是只看厂商宣发材料。Arena 把匿名对战、公开排名和开放数据连接起来,这正适合研究工作流。
第三类是企业或模型团队。About 与 FAQ 页面都提到了 AI Evaluations 服务,这意味着 Arena 不只是面向终端用户的公共产品,也面向需要第三方真实反馈机制的机构客户。如果某个团队想知道新模型在公开任务里的相对表现、用户偏好趋势以及真实世界响应质量,Arena 的公开生态和私有评测服务就有现实价值。
场景上,Arena 很适合以下几种使用方式:一是你已经有一个任务,但不知道该先试哪个模型;二是你想持续追踪近期哪家模型在某赛道进步最快;三是你希望在不被品牌名影响的情况下做盲测比较;四是你关心开放研究、数据集和评测方法,而不仅仅想拿一个“答案生成器”。相比只做聊天的产品,Arena 更像“使用 + 评测 + 观察”的复合型工作台。
优势与限制
Arena 最明显的优势,是把体验、评测和研究连成了一条链。很多多模型平台只能切换模型,但 Arena 通过匿名 Battle Mode 把真实人类偏好变成公开排行榜,再延伸到开放数据与论文,这种闭环是它最稀缺的地方。第二个优势是多模态覆盖足够广,不只做文本聊天,而是扩展到代码、搜索、视觉、文档以及图像和视频相关赛道。第三个优势是方法透明,How It Works、FAQ、Policy、论文和 Hugging Face 数据链接都能直接找到,用户更容易判断这个榜单为什么成立、数据从哪里来。
但它也有很清楚的限制。第一,Arena 的强项是横向比较和理解模型表现,不一定是替代一切专业工具的最佳生产环境。如果你的目标只是稳定长期使用某一个模型并围绕它做深度工作流,专用产品或官方控制台可能更顺手。第二,排行榜虽然比静态 benchmark 更贴近真实使用,但仍然受到参与用户、题目分布、投票行为和平台规则的影响,因此不该把分数当成绝对真理。第三,公开页面没有完整透明地展示普通前台用户的收费结构,所以在做采购或团队导入决策时,仍然需要进一步联系官方确认成本和服务边界。
还有一个现实限制是,Arena 的价值高度依赖你是否真的愿意“比较”和“判断”。如果你只是想快速得到一个答案而不关心不同模型之间的差异,那么它的 Battle、Side by Side 和榜单体系未必能立刻转化为效率收益;但如果你本来就经常在多个模型之间切换,它就会非常有用。
对比与选择建议
如果把 Arena 和 OpenRouter、Poe 这类多模型平台放在一起看,Arena 的独特性不在“接了多少模型”,而在它把真实用户盲测与公开排行榜机制放到了产品正中央。OpenRouter 更偏模型接入与 API 路由,Poe 更偏统一消费界面和 Bot 生态,而 Arena 更像一个把多模型使用、社区偏好收集和公开评测绑在一起的平台。因此它更适合“想比较并理解模型差异”的用户,而不只是“想接更多模型”的用户。
如果把它与 Perplexity 这类强单场景产品相比,Arena 的取胜点也不是某一个垂直任务最好,而是作为观测前沿模型整体表现的窗口更强。你不该指望它在每一个单点任务上都赢过专用工具,但如果你想快速判断文本、代码、搜索、图像或视频任务分别该优先试哪类模型,Arena 的信息密度会更高。
我的建议是:如果你是模型重度用户、开发者、研究者,或者你经常被“到底该先试哪家模型”这个问题困扰,Arena 非常值得加到首批常用工具里;如果你只是想日常固定用一个模型完成任务,Arena 更适合作为辅助判断平台,而不是唯一工作入口。
结论
Arena 值得被收录到 AI模型平台的一站式管理与应用分类里,因为它不是单点聊天工具,而是把前沿模型体验、匿名盲测、公开排行榜、开放数据和企业评测服务整合在一起的复合平台。对普通用户来说,它能帮助你更快理解“哪个模型更适合我当前任务”;对开发者和研究者来说,它则是观察真实人类偏好与模型演化的重要窗口。第一次打开官网时,最值得优先看的顺序通常是:首页看 Battle Mode 入口与产品定位,How It Works 看实际玩法,再看 Leaderboard 判断各赛道模型表现,最后用 FAQ 和 About 理解它的方法与商业边界。
官方来源
- Homepage: https://arena.ai/
- How it works: https://arena.ai/how-it-works
- Leaderboard: https://arena.ai/leaderboard
- About: https://arena.ai/about
- FAQ: https://arena.ai/faq
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/arena-ai.html -APPMARK
一个开源 AI 模型接口管理与分发系统,支持将多种大模型转为 OpenAI 格式调用、支持 Midjourney Proxy、Suno、Rerank,兼容易支付协议。