

开篇摘要
GPT4All 是一套面向本地部署的 AI 聊天与知识库问答工具组合,核心目标是让你在自己的电脑上下载并运行模型,在桌面应用里完成对话、提示词管理与资料检索,同时也能通过 API Server 把同一套本地能力提供给脚本或内部系统调用。它的价值主要体现在两点:一是把“本地模型 + 文档检索(RAG)+ 可用接口”整合成完整工作流;二是在隐私与合规要求较高的场景下,尽量减少把数据发到第三方云服务的必要。
这是什么产品,它解决什么问题
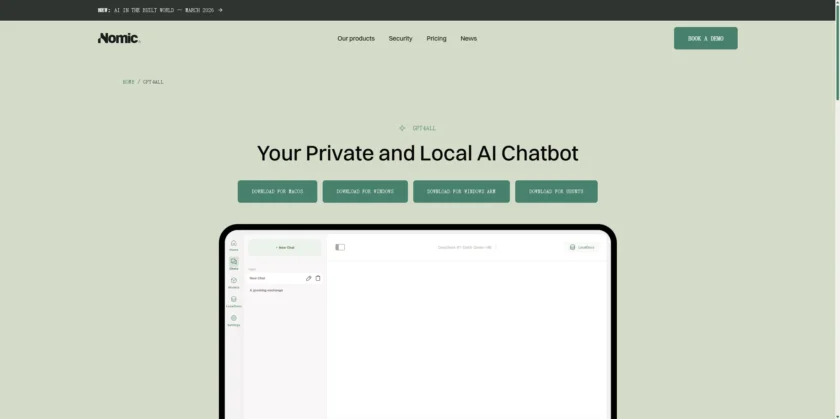
从官网与官方文档的描述来看,GPT4All 由桌面端与配套文档体系构成。桌面端提供跨平台下载入口,用户可以在本机安装后直接体验本地对话,并在界面中选择模型、管理会话和配置推理参数。与“只提供一个模型下载器”的工具不同,GPT4All 更强调把对话、资料接入和服务化输出打通,降低从试用到集成的门槛。
在实际使用里,常见痛点是:一方面团队希望使用大模型能力来做知识问答、文档总结或内部助手;另一方面又不希望把内部文档、客户资料或未公开的研发内容上传到外部服务。GPT4All 的定位就是把这些需求尽量留在本地完成。你可以把它理解为“桌面端的本地 AI 工作台”,并且提供可选的 API Server 作为向外提供能力的入口。
需要说明的是,本地运行的效果与体验会受到硬件条件、模型大小与量化方式影响,官方也会随着版本迭代调整默认推荐与可用功能。因此涉及具体版本、默认模型、参数与兼容性时,应以官网与官方文档的最新说明为准。
核心功能与工作流:对话、模型管理与本地化配置
GPT4All 的核心工作流通常从“选择模型并开始对话”开始。桌面端会提供模型相关入口,帮助你下载并切换不同模型,在同一套 UI 中完成会话管理与提示词组织。对专业用户而言,关键不在于“能不能问答”,而在于能否稳定复用一套提示词、把对话上下文按项目归档,并在需要时导出或迁移。
在配置层面,本地推理一般会涉及最大输出长度、采样策略(例如温度等)以及资源占用控制等参数。GPT4All 的文档与界面强调“可配置”和“可复现”,让你能在不同任务间快速切换策略:例如同一模型在写作润色时偏创意,在检索问答时偏保守。实际参数项与默认值可能随版本变化,建议把“可复制的参数组合”作为团队内部的基线配置,而不是只靠口头经验。
另外,很多本地工具在“能跑起来”之后会卡在“怎么让团队可用”。GPT4All 的思路是把常用动作放进界面里,并提供与 LocalDocs、API Server 的衔接点:你可以先用桌面端完成验证与调试,再把相同的模型与知识库配置迁移到 API Server 或自动化脚本中。
如何开始使用:从下载安装到跑通一条最小闭环
一个更稳妥的上手方式,是把目标拆成三个可验证的小步骤:先确认桌面端能安装并正常对话;再确认本地文档能被索引并可在对话中引用;最后再决定是否需要 API Server 做服务化对接。这样可以避免一上来就把复杂度堆到“部署接口 + 向量库 + 监控”。
按官方 quickstart 的组织方式,你可以先从官网下载安装对应系统的桌面端。完成安装后,打开应用并选择一个模型(或按应用提示下载模型),然后在最简单的聊天窗口里验证输出是否符合预期。接着再进入 LocalDocs 的相关功能,把一小段不敏感资料先建成一个集合,验证索引与引用链路。
当你确认桌面端流程可用,再进入 API Server 文档,按步骤启动本地服务并用简单的请求测试。建议把第一次测试控制在“本机回环调用”层面,例如只在 localhost 上调用接口,确保网络、端口、权限与模型路径都清晰可控,再考虑把它接到更复杂的应用里。
LocalDocs:把本地资料接入 RAG 的方法与注意事项
LocalDocs 是 GPT4All 桌面端的关键能力之一。官方文档提供了 LocalDocs 页面,描述如何创建集合、选择文件夹或资料来源、构建索引,并在对话中引用这些内容。对团队来说,这一步的意义在于:你不再只是在“和模型聊天”,而是把模型变成“带着你的资料回答”。
从工作流角度看,LocalDocs 通常包含三个环节:导入资料、生成向量表示(embedding)并建立索引、检索并拼接上下文到提示词中。索引完成后,你应优先用一些可验证的问题来测试检索质量,例如能否稳定命中关键段落、能否给出可追溯的引用来源。对于经常变动的资料,还需要考虑增量更新与重建索引的成本。
需要谨慎的是,RAG 的“准确性”既取决于模型,也取决于切分策略、向量检索与上下文拼接方式。即便全部在本地运行,也仍然可能出现引用偏差或幻觉式总结。因此更推荐把 LocalDocs 用在“可回溯的资料问答与草稿生成”,并在关键决策场景中保留人工校验环节。
API Server:服务化输出与 OpenAI 兼容接口的价值
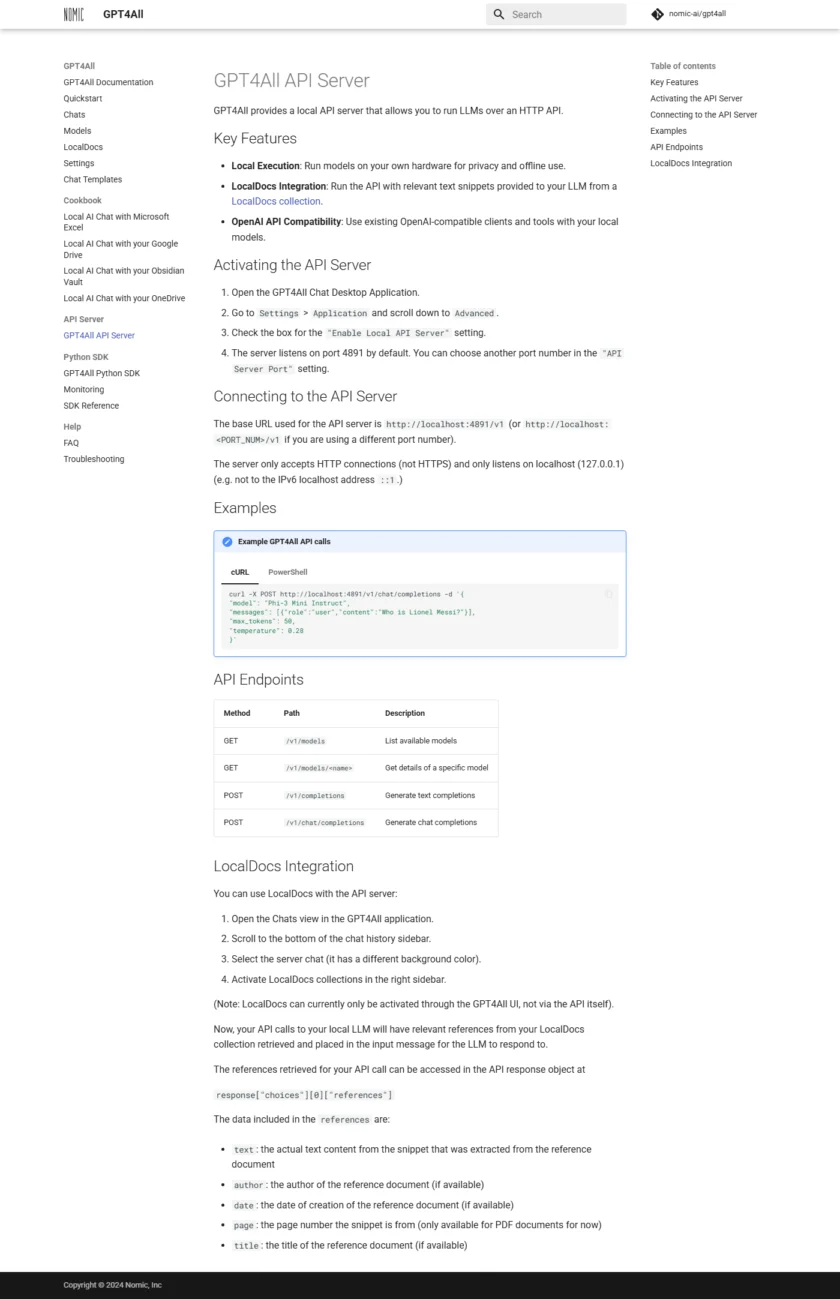
如果你希望把本地能力接入脚本、内部平台或其他产品,API Server 是更合适的形态。官方 API Server 文档页面明确给出默认端口与调用方式,并提供了 curl 等示例来验证接口可用性。对开发者而言,这意味着你可以把 GPT4All 当作一个本地服务来使用,而不是只能在桌面端点来点去。
更重要的一点是,文档显示 API Server 提供 OpenAI 兼容的调用方式,这会显著降低迁移成本:很多现有应用已经围绕 OpenAI 风格接口构建,只要把 endpoint 指向本地服务、替换认证方式与模型名,就能快速完成从云端到本地的切换或双路由。实际兼容范围与参数支持仍需以官方文档为准,尤其是流式输出、工具调用与多模态等能力是否支持。
在工程落地上,建议把 API Server 的使用分两层:第一层是“单机本地调用”,用于验证功能闭环与性能边界;第二层才是“团队或服务器部署”,涉及访问控制、日志、限流与观测指标。只要把这两层拆开,你就能避免在试用阶段就陷入复杂的运维问题。
价格与开源状态:如何判断是否适合你的采购与合规要求
关于价格与授权,最稳妥的做法是直接以官网与官方文档的最新说明为准。一般来说,桌面端工具可能提供免费下载与基础功能,但不同版本、不同平台、以及与企业场景相关的条款可能会变化。对于需要法务与合规审阅的团队,应重点关注其数据处理方式说明、遥测与日志策略、以及是否提供离线部署或可控的更新机制。
关于开源与许可证,如果你计划把 GPT4All 集成到产品中或在企业内部大规模分发,需要进一步核对其开源仓库与许可证文件(例如是否允许商用、是否有分发限制、是否包含第三方模型的额外条款)。如果网络环境导致无法直接访问代码仓库,建议使用代理或在可访问环境下完成一次完整核验,并把结论写入内部文档,避免后续合规返工。
适合谁,以及优势与限制
如果你的首要目标是“把敏感内容尽量留在本地”,并且愿意接受本地推理带来的资源占用与可能的模型质量差异,那么 GPT4All 的桌面端 + LocalDocs + API Server 的组合会更贴近需求。尤其是需要把文档检索与对话结合的场景,例如内部知识库问答、项目资料总结、客服话术草拟与研发文档梳理等。
它的优势在于工作流完整:既能用桌面端做交互与配置,也能用 API Server 做集成;并且 LocalDocs 将“本地资料问答”作为一等公民能力,而不是后置插件。限制同样清晰:本地推理对硬件更敏感,模型选择与量化方式会影响响应速度与质量;同时在缺少联网检索的情况下,模型更适合处理你提供的资料,而不是实时更新的信息检索。
因此,选择建议是:如果你更看重最新信息、稳定的高质量输出和最少的运维成本,云端服务可能更省心;如果你更看重数据边界、可控性与可集成性,本地路线则更可取。GPT4All 的价值在于把本地路线的落地门槛降低到“可从桌面端开始逐步演进”。
官方来源
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/gpt4all.html -APPMARK
企业级 Work AI 平台:连接组织内部数据与权限,在统一入口提供搜索、对话式问答与助手协作(Glean Chat / Glean Assistant),支持引用与可追溯的工作流落地。