

Groq 是一家领先的 AI 基础设施公司,致力于通过其自主研发的 LPU(语言处理单元)推理引擎,彻底改变大语言模型的推理速度。Groq 的核心优势在于解决了传统 GPU 在处理实时 AI 任务时的内存带宽瓶颈,实现了极低延迟和极高吞吐量的推理表现。平台目前深度优化并托管了 Llama 3、Mixtral 以及 Gemma 等主流开源大模型,能够以每秒数百个 Token 的速度生成文本,为用户提供近乎瞬时的交互体验。无论是通过 GroqChat 进行网页对话,还是利用兼容 OpenAI 标准的 API 进行集成,开发者都能以极具竞争力的成本构建实时语音助手、自动化代理等下一代 AI 应用。
Groq是什么?
Groq 是一家领先的 AI 基础设施公司,致力于通过创新的硬件技术彻底改变大语言模型(LLM)的推理速度。Groq 的核心竞争力在于其自主研发的 LPU(Language Processing Unit,语言处理单元)推理引擎。这是一种专为大模型设计的全新处理器架构,旨在解决传统 GPU 在处理实时 AI 任务时存在的内存带宽瓶颈,从而实现极低延迟的推理表现。
核心定位与技术优势
- 极致推理速度:Groq 能够以每秒数百个 token 的速度运行主流大模型,其推理性能通常比传统的云端 GPU 方案快数倍,实现了真正的“秒出”体验。
- 低延迟响应:通过消除计算过程中的不确定性,Groq 实现了近乎瞬时的首字响应(TTFT),非常适合需要实时交互的 AI 应用场景。
- 确定性架构:LPU 采用确定性指令流处理,能够提供可预测的性能表现,确保在不同负载下都能保持稳定的高吞吐量。
支持的模型与功能
Groq 平台目前主要托管并加速业界领先的开源大语言模型,通过其高性能架构赋予这些模型超越原生的运行效率:
| 模型系列 | 代表型号 | 核心优势 |
|---|---|---|
| Meta Llama | Llama 3 (8B, 70B) | 在 Groq 上可实现极速的逻辑推理与对话响应 |
| Mistral AI | Mixtral 8x7B | 结合混合专家模型架构,提供高效的多任务处理 |
| Google Gemma | Gemma 7B / 2B | 针对轻量级任务提供极致的吞吐性能 |
使用与获取方式
- GroqChat:面向普通用户的 Web 交互界面。用户可以直接在浏览器中选择不同的开源模型进行对话,直观感受 LPU 带来的极速生成效果。
- GroqCloud (API):面向开发者的云服务平台。提供完全兼容 OpenAI API 格式的接口,开发者只需修改 Base URL 和 API Key,即可将现有的 AI 应用无缝迁移至 Groq 引擎。
- Playground:在 GroqCloud 中提供的测试环境,允许开发者实时调整模型参数(如 Temperature、Top-P)并监控推理速度(Tokens Per Second)。
Groq 的愿景是让 AI 推理变得像电力一样即时且廉价。通过打破速度障碍,它为下一代实时 AI 应用(如实时语音翻译、高频自动化决策、复杂长文本即时分析)提供了坚实的底层支撑。
核心功能
产品定位与核心技术
Groq 是全球领先的 AI 推理加速平台,致力于通过创新的硬件架构解决大语言模型(LLM)的推理延迟问题。其核心竞争力源于自主研发的 LPU™ (Language Processing Unit) 推理引擎。不同于传统的 GPU,LPU 专为处理序列数据(如文本)而设计,能够消除计算中的不确定性,提供极高的吞吐量和极低的延迟,使 AI 交互达到近乎实时的水平,彻底改变了生成式 AI 的用户体验。
核心功能特性
- 极致的推理性能:Groq 在运行主流开源模型(如 Llama 3.1 70B)时,推理速度可突破每秒数百个 Token,其生成速度通常比传统云服务商快 10 倍以上。
- 超低延迟响应:具备极短的首字生成时间(TTFT),能够实现毫秒级的反馈,非常适合需要即时交互的实时对话、智能客服、代码实时补全及自动化代理(Agents)场景。
- 主流开源模型集成:平台全面支持并优化了当前最顶尖的开源大模型,包括 Meta 的 Llama 3.1/3.2 系列、Mistral 的 Mixtral 8x7B 以及 Google 的 Gemma 系列。
- 高能效与确定性:LPU 架构在提供高性能的同时,通过确定性的指令流减少了计算资源的浪费,为大规模 AI 应用部署提供了更具成本效益的硬件方案。
技术规格与优势对比
| 维度 | Groq LPU 表现 |
|---|---|
| 核心架构 | 确定性张量流处理器,无缓存缺失导致的延迟波动。 |
| 推理吞吐量 | 支持高达 500+ Tokens/s 的并发处理能力(视具体模型而定)。 |
| API 兼容性 | 完全兼容 OpenAI API 格式,开发者仅需更改 Base URL 即可实现无缝迁移。 |
使用方式与获取途径
- GroqChat 交互界面:普通用户可以直接访问 GroqChat 网页端,在下拉菜单中切换不同的开源模型,直接体验极速对话。
- GroqCloud 开发者平台:开发者可以注册 GroqCloud 账号并创建 API Key。平台提供了完善的使用量监控、速率限制管理以及针对 Python 和 Node.js 的官方 SDK。
- Playground 调试工具:在云端控制台中,用户可以手动调整 Temperature、Top-P、Stream 等参数,实时预览不同配置下的推理速度和输出质量。
Groq 目前采取“免费 + 付费”的模式,为开发者提供充足的免费测试额度(Rate Limits),同时也为有高并发需求的企业用户提供按量计费的生产级服务。
如何开始使用?
Groq 重新定义了 AI 推理的速度标准。作为一家领先的 AI 基础设施提供商,Groq 致力于通过其创新的 LPU™(Language Processing Unit)架构,为开发者和企业提供近乎实时的生成式 AI 体验。与传统的 GPU 方案不同,LPU 专为大语言模型(LLM)的计算特性设计,能够显著消除推理过程中的瓶颈。无论您是寻求极速对话体验的普通用户,还是需要高性能推理接口的开发者,都可以通过以下方式快速接入 Groq 的服务。
核心接入方式
- GroqCloud 开发者平台: 专为技术人员设计,提供完整的 API 文档、模型测试沙盒(Playground)以及 API 密钥管理功能,支持高度自定义的参数配置。
- Groq Chat 交互界面: 网页端直观对话窗口,用户可以直接在浏览器中与搭载 LPU 加速的各种开源大模型进行实时交互,直观感受每秒数百个 Token 的生成速度。
快速开始步骤
- 账号注册: 访问 Groq 官方网站,通过电子邮箱或第三方授权方式完成注册,登录后即可进入 GroqCloud 控制台。
- 模型测试: 进入 Playground 页面,在模型下拉菜单中选择所需的开源模型(如 Llama 3 或 Mixtral),输入提示词并点击运行,即可实时查看推理延迟和吞吐量数据。
- 创建 API Key: 在侧边栏导航至“API Keys”选项卡,点击“Create API Key”按钮。请务必妥善保存此密钥,它是您调用 Groq 推理服务的唯一凭证。
- 环境集成: 根据官方提供的 API 文档,使用 Python 或 Node.js SDK 将 Groq 接口集成到您的应用程序中。Groq 的 API 接口与 OpenAI 兼容,极大降低了迁移成本。
支持的主流模型列表
| 模型系列 | 典型代表 | 核心优势 |
|---|---|---|
| Meta Llama | Llama 3 (8B/70B) | 卓越的逻辑推理与通用对话能力 |
| Mistral AI | Mixtral 8x7B | 高效的混合专家架构,适合复杂任务 |
| Google Gemma | Gemma 7B / 2B | 轻量化指令遵循,适合特定场景优化 |
为什么选择 Groq?
Groq 的核心优势在于其确定性的计算性能。在处理大规模并发请求时,LPU 能够保持稳定的低延迟输出,这对于构建实时语音助手、自动化 Agent 代理以及需要即时反馈的交互式应用至关重要。通过 GroqCloud,开发者可以以极具竞争力的成本获取目前市面上最快的开源模型推理服务。
价格或获取方式
Groq 定位于全球领先的极速 AI 推理平台,其核心竞争力在于自研的 LPU(Language Processing Unit)硬件架构,专门为大语言模型(LLM)提供远超传统 GPU 的推理速度。Groq 并不直接研发模型,而是通过优化开源模型的运行效率,为开发者和企业提供极致的性能体验。
获取与使用方式
- GroqChat 网页端:用户可以通过 Groq 官网的对话界面直接体验。目前支持 Llama 3、Mixtral、Gemma 等主流开源模型,用户无需配置环境即可感受每秒数百个 Token 的生成速度。
- GroqCloud 开发者平台:开发者可以注册 GroqCloud 账号获取 API Key。该 API 接口高度兼容 OpenAI 标准,支持流式输出,方便开发者将极速推理能力集成到现有的应用程序或工作流中。
- Playground 测试场:在 GroqCloud 中提供可视化测试环境,允许用户调整温度、Top-P 等参数,实时观察不同模型的响应延迟和吞吐量。
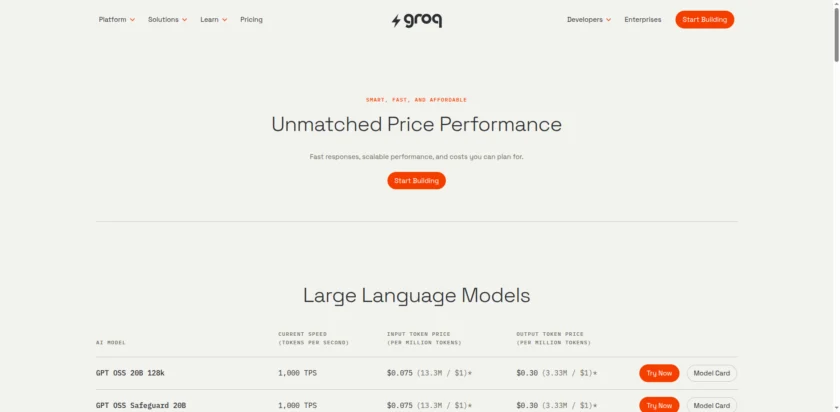
价格方案
Groq 采取了极具竞争力的定价策略,主要分为以下几个层级:
| 模型名称 | 输入价格 ( 每 1M Tokens) | 输出价格 ( 每 1M Tokens) |
|---|---|---|
| Llama 3 8B | $0.05 | $0.08 |
| Llama 3 70B | $0.59 | $0.79 |
| Mixtral 8x7B | $0.24 | $0.24 |
| Gemma 7B | $0.07 | $0.07 |
免费层级(Free Tier):Groq 目前为注册用户提供免费的使用额度,但在请求频率(RPM)和每分钟 Token 数(TPM)上设有一定限制,适用于个人开发者进行原型开发和技术测试。对于需要更高并发和稳定保障的企业用户,Groq 提供按需付费模式以及针对特定硬件需求的私有化部署方案。
适合谁?
Groq 定位于全球领先的极速 AI 推理平台,核心竞争力在于其自研的 LPU(Language Processing Unit)推理引擎。它打破了传统 GPU 在大语言模型推理上的速度瓶颈,专为追求“零延迟”响应的开发者和企业设计,是目前运行开源大模型速度最快的方案之一。
核心受众与应用场景
- 实时交互应用开发者: 适用于需要极高响应速度的场景,如实时语音对话助手、即时翻译系统、高频智能客服以及需要毫秒级反馈的交互式 AI 代理。
- 开源模型深度用户: 针对希望以极致性能运行 Llama 3、Mixtral、Gemma 等主流开源模型的团队,Groq 提供了远超传统云服务商的 Token 输出速率。
- 追求效率的专业人士: 厌倦了传统大模型“打字机”式的缓慢输出,通过 GroqChat 可以获得近乎瞬时的全文生成体验,大幅提升内容创作和信息检索效率。
- 企业级架构师: 寻求高吞吐量、低延迟且具备成本效益的推理基础设施,以替代昂贵且供应紧张的传统 GPU 集群。
产品核心能力对比
| 维度 | Groq LPU 推理 | 传统 GPU 推理 |
|---|---|---|
| 推理速度 | 极速(通常可达 500-800 tokens/s) | 中等(受限于显存带宽瓶颈) |
| 延迟表现 | 极低延迟,输出几乎无感知等待 | 存在明显的首字延迟和生成停顿 |
| 并发处理 | 确定性计算,高并发下表现稳定 | 并发增加时延迟波动较大 |
获取与使用方式
- GroqChat (Web 端 ): 访问官网提供的对话界面,直接选择不同的开源模型进行极速对话体验,无需复杂配置。
- GroqCloud API: 开发者可以申请 API 密钥,通过兼容 OpenAI 标准的接口协议,将 Groq 的推理能力无缝集成到现有应用程序中。
- Playground: 在开发者实验室中实时调试模型参数(如 Temperature、Top-P),并直观查看每秒生成的 Token 数和总延迟数据。
总之,如果您正在寻找能够让 Llama 或 Mixtral 等模型跑出“起飞”速度的平台,或者需要构建对实时性要求极高的 AI 产品,Groq 是目前市场上的首选基础设施。
优势与局限
Groq 定位于全球领先的 AI 推理加速平台,其核心竞争力在于自主研发的 LPU™(Language Processing Unit)推理引擎。与传统的 GPU 方案不同,LPU 专为大语言模型的序列化计算而设计,旨在消除内存瓶颈,实现极低延迟和极高吞吐量的实时响应。
核心优势
- 极致的推理速度: Groq 在运行 Llama 3、Mixtral 等主流开源模型时,推理速度可达每秒数百个 Token。这种近乎瞬时的生成能力,使其成为目前市场上响应最快的 AI 推理平台之一,能够满足对实时性要求极高的应用场景。
- LPU 架构创新: 采用确定性指令流处理架构,通过精确控制时钟周期来管理数据流。这种设计消除了 GPU 在推理过程中常见的调度开销和内存带宽限制,确保了生成过程的稳定性和极高的计算效率。
- 开发者友好型集成: 提供与 OpenAI 完全兼容的 API 接口。开发者只需更改 Base URL 和 API Key,即可将现有应用无缝迁移至 Groq 平台,显著降低了技术适配和迁移的成本。
- 高性价比: 凭借硬件层面的高能效比,Groq 能够以更低的能耗完成大规模推理任务,从而在 API 定价上展现出极强的竞争力,尤其适合需要处理海量并发请求的企业级应用。
局限性
| 维度 | 说明 |
|---|---|
| 模型支持范围 | 目前仅支持 Llama、Mixtral、Gemma 等主流开源模型,无法直接运行 GPT-4、Claude 或 Gemini 等闭源商业模型。 |
| 硬件内存限制 | 相比于拥有海量显存的顶级 GPU,单个 LPU 的 SRAM 容量较小。在处理超大规模参数模型或超长上下文(Context Window)时,需要复杂的硬件集群扩展。 |
| 功能单一性 | Groq 的硬件架构专为推理(Inference)优化,并不支持模型的训练(Training)或深度微调(Fine-tuning)任务。 |
获取与使用方式
用户可以通过以下两种主要途径获取 Groq 的服务:
- GroqCloud: 专为开发者设计的云平台。用户可以在此获取 API 密钥、查阅技术文档,并在 Playground 环境中实时调试不同模型的参数与性能表现。
- GroqChat: 面向终端用户的在线对话界面。用户无需配置环境,即可直接在浏览器中体验由 LPU 驱动的极速 AI 对话功能,直观感受不同开源模型的生成效果。
Groq 的核心使命是通过硬件革新打破 AI 推理的性能瓶颈,为下一代实时 AI 应用提供坚实的算力底座。
结论
Groq 凭借其首创的 LPU™(Language Processing Unit)推理引擎,重新定义了通用大语言模型的运行速度。作为一家专注于推理性能的 AI 硬件与软件平台,Groq 解决了传统 GPU 在处理大模型时常见的延迟瓶颈,为开发者提供近乎瞬时的文本生成体验,是目前全球领先的实时 AI 推理基础设施。
核心价值与产品定位
- 极致速度:提供每秒数百个 Token 的推理速度,显著优于传统云端 GPU 推理方案。
- 低延迟架构:专为顺序工作负载设计,确保实时对话、同声传译和复杂逻辑推理的流畅性。
- 主流模型支持:深度优化了 Llama 3、Mixtral、Gemma 等开源大模型,确保高性能输出。
获取与使用方式
| 获取途径 | 功能说明 |
|---|---|
| GroqCloud Playground | 无需编程,直接在浏览器中测试不同模型的推理速度、延迟及生成效果。 |
| API 接口集成 | 完全兼容 OpenAI API 标准,支持通过 Python、Node.js 等 SDK 快速将现有应用迁移至 Groq。 |
| 开发者控制台 | 提供 API Key 管理、使用量监控、限流说明及详细的集成文档。 |
用户可以通过访问 Groq 官网 (groq.com) 并注册 GroqCloud 账号来免费或付费获取 API Key。无论是构建实时语音助手、自动化代码生成工具,还是大规模文本分析应用,Groq 都是目前追求极致推理效率、降低交互延迟的首选平台。其 LPU 技术不仅提升了用户体验,也为下一代实时 AI 应用的爆发奠定了硬件基础。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/groq.html -APPMARK
百度推出的 Web 版 AI 助手,可用于聊天问答、文案创作、阅读文档、智能翻译,以及画图识图等任务。