

Metavoice 是一个以“对话式语音”为核心的语音 AI 工具与平台。官方站点 themetavoice.xyz 会跳转到 metavoice.io,其产品页面强调“面向语音 Agent 的 Duplex Speech-to-Speech(双向语音到语音)能力”,并将 Speech-1 作为对话式语音模型进行介绍。除了托管式产品线,Metavoice 也维护了开源项目:例如 MetaVoice-1B(TTS 模型与推理代码)以及 MetaVoice Live(实时变声/语音转换方向的开源实现)。因此,如果你的需求涵盖“语音生成(TTS)”“语音克隆(zero-shot cloning)”“实时变声(voice conversion)”或“面向语音 Agent 的低延迟对话语音”,Metavoice 往往会以“托管服务 + 开源组件”的组合形式进入你的选型列表。
但语音类工具最容易踩坑的地方也在这里:能力越接近“复刻某个人的声音”,合规与授权边界就越关键。即便某个模型/代码以开源许可证发布,许可证也只解决“你是否被允许使用这份代码或权重”的问题,并不会自动赋予你“使用某个具体声音身份、或使用某段录音素材”的权利。下文会把 Metavoice 的主要能力、开源与商用边界、以及语音克隆类能力的合规要求讲清楚,方便你在落地时把风险控制写进流程,而不是靠“事后解释”。
能力版图:Speech-1 的对话式语音与面向语音 Agent 的低延迟体验
在官网的 Speech 页面与博客文章中,Metavoice 将 Speech-1 描述为“Conversational Speech Model”,并强调它面向语音 Agent 场景:不仅要“发音像人”,还要在对话中做到更像人类的节奏与反馈,例如自然的停顿、打断(interruption)、对用户说话节奏的跟随,以及更符合对话语境的韵律表达。官方同时强调了实时性指标:在“Duplex conversational speech”场景下,给出了 p90 TTFA(time-to-first-audio)小于 250ms 的量级目标,用来说明其面向实时对话的工程取向。
如果你做的是语音助手、客服外呼、语音陪伴、口语练习、或任何“边听边说”的语音交互,体验上真正决定成败的往往不是“单句 TTS 的音色有多好听”,而是整套对话行为是否自然:系统能否在用户打断时及时停下,能否在用户犹豫时用短反馈承接,能否在不同语境下用不同的语气与语速。这类能力更接近“对话语音系统”而不是“离线配音工具”,因此也更依赖托管式平台(例如平台侧的流式接口、会话状态管理、音频管线与延迟优化)。
需要注意的是:Speech-1 属于官方产品线的一部分,其授权与使用边界通常以平台条款与产品政策为准;而 MetaVoice-1B / MetaVoice Live 等开源项目,则以各自仓库中的许可证为准。两者要分开看,避免把“开源模型能做的事”与“托管产品允许你怎么用”混为一谈。
MetaVoice-1B(开源 TTS):从文本到语音,以及 zero-shot 语音克隆的能力边界
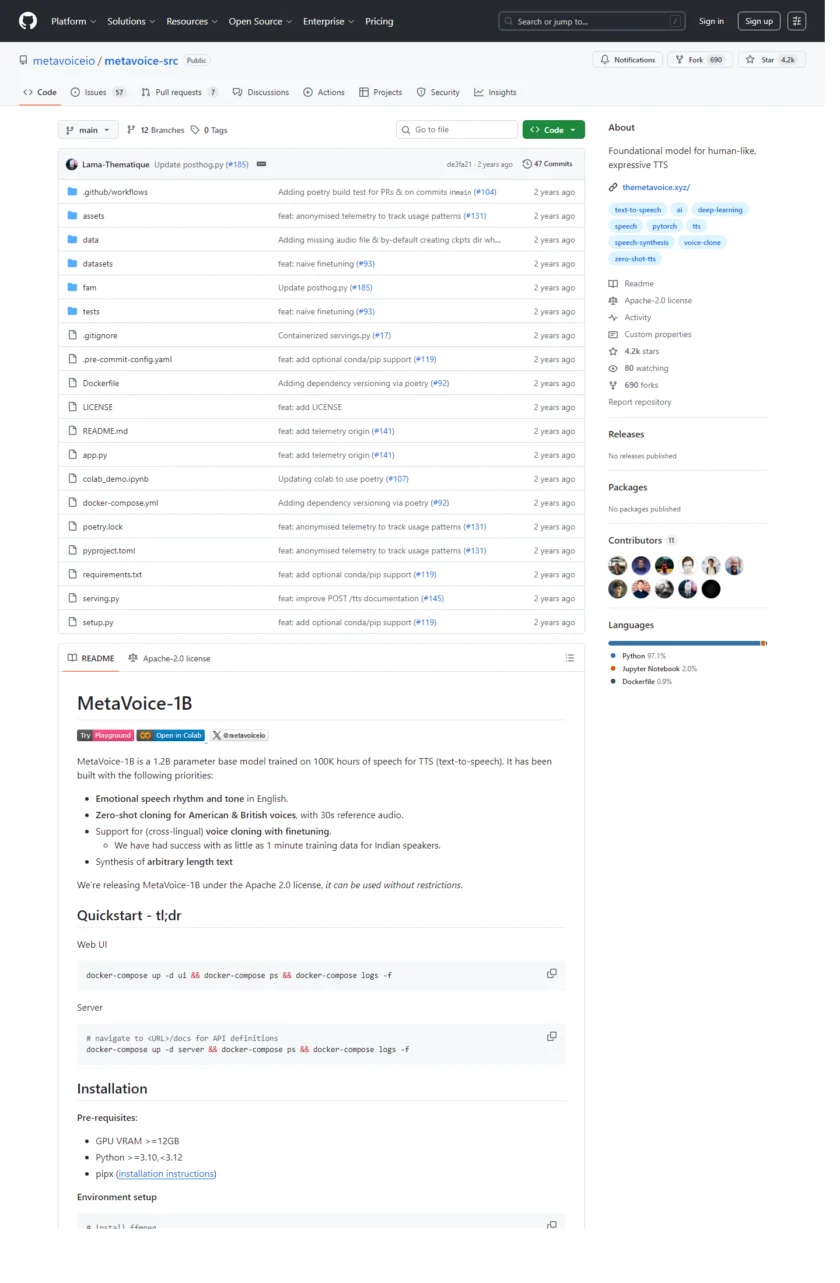
在官方 GitHub 仓库中,Metavoice 发布了 MetaVoice-1B(约 1.2B 参数)的 TTS 模型与推理/部署相关代码。官方 README 明确写到该模型支持 zero-shot voice cloning:提供约 30 秒的参考音频,就可以在不额外训练的情况下生成带有相似音色特征的语音;并且强调可生成任意长度的语音输出。这意味着它不仅可用于“统一音色的内容生产”,也可能被用来做“拟声/复刻”的工作流,因此合规控制必须前置。
从工程落地角度,MetaVoice-1B 的开源仓库同时提供了可用性更高的入口:例如通过 Docker Compose 启动一个本地 UI 与推理服务(仓库 README 给出了对应命令与端口说明)。对于团队来说,这种“可本地自托管”的形态有两个现实价值:
第一,你可以把语音生成链路放在自己的基础设施里,减少把文本与参考音频上传到第三方服务的需求,从而降低隐私与数据合规风险;第二,你可以把合规校验做成强制步骤,例如在进入推理前检查参考音频的授权证明、在输出时强制加上标注水印或元数据标记、在外发时绑定项目工单与审批记录。
与此同时,开源并不等于“无限制使用任何人的声音”。即使模型层面支持 zero-shot 克隆,你也应该把它当作“对授权管理要求更高的能力”,而不是“更强的音色选择器”。最稳妥的落地方式是:只克隆你拥有权利的声音(本人同意、合同授权、或明确的可商用授权素材),并在流程里保存可审计证据。
语音克隆与变声的合规底线:许可不等于授权,授权要可审计
语音克隆(voice cloning)与变声(voice conversion)在合规上最容易被误解的一点是:很多人把“模型是开源的”误读为“我可以用它复刻任何人的声音”。这是不成立的。开源许可证(如 Apache-2.0、GPL-3.0)解决的是软件与模型权重的使用与再分发规则;但“某个真实人物的声音”涉及人格权/肖像权的衍生保护、隐私、以及在不同司法辖区下的反冒充与反欺诈法规约束。即便你完全遵守了开源许可证,如果你在没有授权的情况下克隆某个人的声音并对外传播,依然可能构成侵权或违法。
因此,对语音克隆类能力,建议把合规边界写成可执行的“硬规则”,而不是一句口号:
1)必须获得明确授权:克隆或拟声对象应当是你本人、你公司签约的配音/主播、或提供了明确可商用授权的声音素材。授权应覆盖用途(广告/客服/内容生产/游戏等)、地域、期限、可否二次加工、以及是否允许生成“听起来像本人在说话”的内容。
2)不得用于冒充与误导:禁止把生成语音伪装成真实录音证据,禁止用于诈骗、虚假背书、诱导转账、或任何以“让听众误以为某人亲口说过”为目的的传播。
3)对外发布必须做清晰标注:在视频描述、片头片尾、播客口播或产品 UI 中明确说明“本内容包含 AI 生成/转换语音”。如果你的业务场景本身容易引发误解(例如金融建议、政务信息、医疗建议),标注应该更醒目,且配合人工审核。
4)建立可审计链路:为每次克隆任务记录参考音频的来源、授权文件、提交人、审批人、生成时间、输出用途与投放渠道,必要时保留哈希或签名用于追溯。对企业来说,这比“技术上能不能生成”更重要。
5)最小化上传与暴露:能在本地或自有环境完成的,不要默认把参考音频与原始文本上传到第三方。即便使用托管平台,也应避免上传含有敏感个人信息或受保密协议约束的音频内容。
这些规则并不会限制你做“合法合规的声音产品”,反而能让团队在扩张与外部审计时更稳:当你能把授权、标注、审计做成流程,语音克隆就从“高风险能力”变成“可控能力”。
开源与商用边界:Apache-2.0 的 MetaVoice-1B、GPL-3.0 的 MetaVoice Live,以及托管产品的使用约束
MetaVoice-1B(metavoice-src 仓库):官方在 README 中明确该模型采用 Apache License 2.0,并写明“可以不受限制地使用(used without restrictions)”。从许可证角度,这通常意味着你可以将模型与代码用于研究或商业用途,也可以在遵守 Apache-2.0 条款(保留版权与许可声明、处理 NOTICE 等)的前提下进行再分发与二次开发。但请再次注意:这不等于你可以使用任何人的声音进行克隆,声音权利与内容权利仍需另行获得授权。
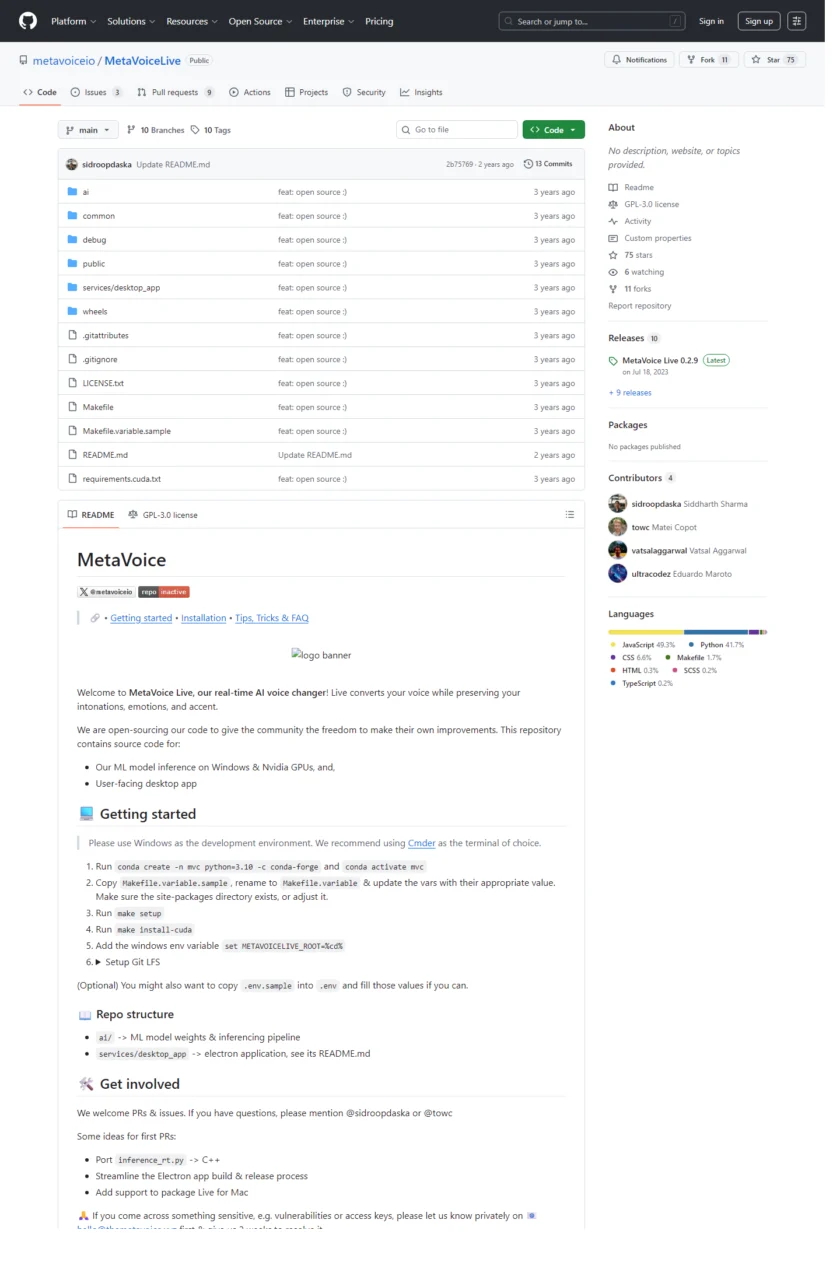
MetaVoice Live(MetaVoiceLive 仓库):该项目在 GitHub 上标注为 GPL-3.0。GPL 的核心影响在于“分发”与“衍生作品”的开源义务:如果你修改并分发该项目或将其以某些方式与产品形成衍生作品,你可能需要按照 GPL-3.0 的要求开放相应源代码并提供许可证文本。对于企业商用落地,这会直接影响你的代码合规策略与发布方式,因此应在引入前由工程与法务一起评估集成形态。
Speech-1 与平台服务:官网将 Speech-1 与平台入口(如 platform.metavoice.io)作为产品线的一部分进行呈现。对于托管服务,你的使用边界一般由平台条款、隐私政策、以及产品侧的安全政策共同决定。即便你使用的是“官方平台”,也仍然需要在业务侧落实授权、标注与反冒充控制,因为平台条款通常会明确禁止诈骗、冒充与违法用途。
一个实用的分界方式是:当你需要强合规、强可审计、以及最小化外传数据时,优先考虑以开源模型自托管为核心,并把平台能力作为补充;当你最在意“低延迟对话语音体验”与“端到端对话系统行为”时,托管平台往往更省工程成本,但你要更严格地约束输入数据与输出发布流程。
隐私与数据处理:参考音频、文本内容与输出音频的最小化原则
无论你采用托管平台还是自托管开源模型,语音项目的隐私风险都可以归结为三类数据:
1)参考音频:用于 zero-shot 克隆或风格控制的音频片段。它通常直接携带可识别身份的声音特征,属于高敏数据。建议只保留业务所需的最小长度,并对存储与访问做权限控制;对外协作时尽量用脱敏后的样例或由授权方提供专用录音。
2)文本内容:在客服、医疗、金融等场景里,文本可能包含个人隐私、交易信息、健康信息或敏感意图。建议在进入推理前做结构化脱敏与敏感字段剔除,并把原始文本与生成任务的绑定信息(如工单号)分离存储。
3)输出音频:生成结果在传播后最难回收。对外发布时应强制标注为 AI 生成/转换,并在素材管理系统里保留“生成来源与授权证明”的链接,避免后续在二次使用时失去上下文,导致误用。
如果你无法在组织内建立上述数据治理能力,最稳妥的做法是收缩场景:只做自有声音、只做内部测试、只在受控渠道发布。语音克隆不是不能做,而是必须“先把授权与审计做出来,再谈规模化”。
选型建议:用 Metavoice 的三种典型路径
路径 A:做语音 Agent 的对话体验(优先 Speech-1 平台)。如果你的目标是实时对话,关注打断、承接、对话节奏与低延迟,优先从官网的 Speech-1 与平台入口开始评估。重点验证:端到端延迟、流式稳定性、在噪声与口音条件下的对话自然度,以及你是否能在产品层面加上明确标注与滥用防控。
路径 B:做内容生产或产品原型的可控 TTS(优先 MetaVoice-1B 自托管)。如果你更看重可控性、隐私与可审计,MetaVoice-1B 的开源仓库是更好的起点。你可以在私有环境里搭建推理服务,并把“授权校验、内容审核、对外标注”写进 CI/CD 或内容管理流程。
路径 C:做实时变声或语音转换(关注 MetaVoice Live 的 GPL 约束)。如果你需要实时变声能力,可以关注 MetaVoice Live,但要提前评估 GPL-3.0 对你的分发模式与闭源产品形态的影响,避免后期合规返工。
无论选哪条路径,都建议把“授权与合规”作为产品需求的一部分:你不仅在交付语音能力,也在交付一套能被审计、能被解释、能对滥用说不的工作流。
官方来源
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/metavoice.html -APPMARK
面向音乐与多媒体创作的一体化 AI 音频工作台。