


Stable Audio 是 Stability AI 开发的一套 AI 工具,用于生成和操作音频,包括 Stable Audio 2.0(用于长音乐曲目)和 Stable Audio Open(用于短音频样本)。
什么是 Stable Audio?
Stable Audio 是一组由 Stability AI 开发的 AI 驱动工具,旨在帮助用户使用人工智能创建和修改音频内容。它包括两个主要版本:Stable Audio 2.0 和 Stable Audio Open,每个版本针对不同用途设计。
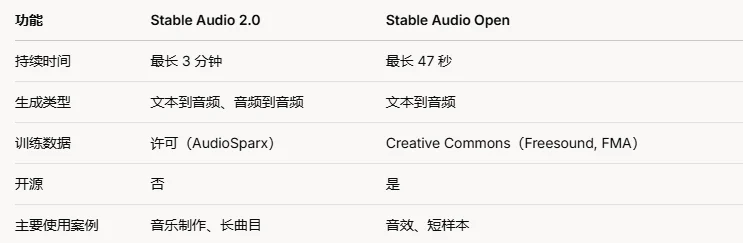
- Stable Audio 2.0:专注于生成完整音乐曲目,能从简单的文本提示生成长达三分钟的高质量音频(44.1 kHz 立体声)。它还提供独特的音频到音频生成功能,用户可以上传音频样本并使用自然语言指令进行转换。它使用 AudioSparx 的许可数据集进行训练,确保创作者获得公平补偿。
- Stable Audio Open:这是一个开源模型,优化用于生成短音频样本(如音效或制作元素),从文本提示生成,最长 47 秒(44.1 kHz 立体声)。它使用 Freesound 和 Free Music Archive 等 Creative Commons 数据训练,使其免费且易于访问。
这种双重方法使 Stable Audio 具有多功能性,适合专业音乐制作人和寻找快速音频解决方案的业余爱好者。
如何使用 Stable Audio?
开始使用 Stable Audio 很简单,具体取决于您选择的版本:
Stable Audio 2.0
- 访问 stableaudio.com 网站并注册或登录。
- 输入描述性的文本提示生成音乐,例如“欢快的流行歌曲,带有钢琴和鼓”。
- 可选地,上传音频样本并使用提示转换它,例如“将其变成爵士版本”。
- 下载生成的音频用于您的项目。
对于 Stable Audio Open
- 转到 Hugging Face 页面下载模型。
- 使用 stable-audio-tools 库设置环境,遵循提供的文档。
- 使用文本提示生成短音频剪辑,例如“碎石上的脚步声”或“森林的氛围音”。
两个版本都用户友好,但 Stable Audio Open 由于其开源性质需要更多技术设置。
音频到音频转换
Stable Audio 2.0 的一个有趣功能是使用文本提示转换现有音频,这在其他 AI 音频工具中不常见。例如,您可以上传鼓循环并要求“使其听起来像摇滚民谣”,为音频编辑提供创造性灵活性。
Stable Audio 的全面分析
Stable Audio 代表了 AI 驱动音频生成领域的重大进步,由 Stability AI 开发,这家公司以其生成 AI 工作而闻名,例如用于图像的 Stable Diffusion。本分析深入探讨其定义、功能、使用和更广泛的影响,基于截至 2025 年 3 月 18 日的信息。
功能和特点
Stable Audio 的功能因版本而异,反映了它们的不同目标受众:
- Stable Audio 2.0 功能:
- 文本到音频生成:用户可以描述所需的音频,例如“带有合成垫的舒缓环境曲目”,模型生成具有连贯音乐结构的完整曲目。
- 音频到音频生成:此功能允许用户上传音频样本并使用提示转换,例如“使这鼓点听起来电子化”。如 Stable Audio 2.0 Review 评价中所述,这对重新混音或增强现有音频特别有用。
- 高质量输出:它生成 44.1 kHz 立体声音频,适合音乐制作和流媒体的专业使用。
- Stable Audio Open 功能:
- 文本到音频生成:专注于短剪辑,能生成如“门吱吱作响”或“森林中的鸟鸣”等声音,理想用于音效设计。
- 开源可访问性:可在 [Hugging Face](https://huggingface.co/stabilityai/stable-audio-open-1.0) 下载,尤其适合使用 A6000 GPU 本地微调,如 [Stable Audio User Guide](https://stableaudio.com/user-guide) 用户指南所述。
- 训练数据:使用近 500,000 条 Creative Commons 许可下的录音训练,仔细筛选以排除受版权保护的材料,如研究论文详述。
使用和快速开始
使用 Stable Audio 取决于版本,需要不同程度的技术专长:
- Stable Audio 2.0 使用:
- 用户可以访问 stableaudio.com 注册并开始生成音频。过程包括输入文本提示,可选上传音频样本进行转换,并下载结果。Stable Audio User Guide 用户指南提供优化提示的建议,例如描述性和具体性。
- Stable Audio Open 使用:
- 对于 Stable Audio Open,用户需要从 Hugging Face 下载模型,并使用 stable-audio-tools 库设置环境,如 How to Use Stable Audio Open 1.0 指南解释。这涉及安装依赖和运行推理等技术步骤,适合有编程知识的用户。
- 有效使用的提示
要最大化 Stable Audio 的潜力,用户可以遵循以下提示:
- 文本提示:描述性,例如“快节奏的电子舞曲,带有重低音”,有效引导 AI。
- 音频到音频生成:选择相关音频样本,使用清晰提示,例如“将这把原声吉他变成摇滚即兴演奏”,获得更好结果。
- 实验:尝试不同的提示变体和设置,了解模型能力,如 Stable Audio User Guide 用户指南建议。
Stable Audio 及其两个版本提供了一个强大的音频生成套件,满足从长格式音乐到短音效的多样需求。其伦理训练数据实践和用户友好界面使其成为创作者和研究人员的宝贵工具,截至 2025 年 3 月 18 日。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/stable-audio.html -APPMARK
Bark 是由 Suno 推出的开源的文本转音频模型。 它的目标是通过自然语言处理技术,将输入的文本转换为高度逼真的音频,包括多语种自然语言、音乐、背景噪音和简单的声音效果。