

Tabby 是一款开源、自托管(self-hosted)的 AI 编程助手,官方将其定位为 GitHub Copilot 的“可自建替代方案”。它的核心思路是把 AI 编程能力做成一套可运维的工程系统:你在自己的服务器或内网环境部署 Tabby Server,选择合适的代码补全模型与对话模型,然后通过 IDE 插件把能力接入 VS Code、JetBrains 等编辑器,获得多行补全、Chat 问答、解释代码与内联编辑等体验。
与闭源云端 SaaS 不同,Tabby 强调 on-premises / self-hosted:模型推理、日志与访问控制都在你可控的基础设施中完成。官方 GitHub README 也明确强调了几个工程化特性:自包含(不依赖 DBMS 或云服务)、提供 OpenAPI 接口便于集成、支持消费级 GPU。对希望把代码与研发数据留在内网、或需要可审计与成本可控的团队来说,这些特性通常比“开箱即用”更重要。
1. 架构与工作方式:服务端统一治理,插件端提供交互
Tabby 的形态可以理解为两层:
Tabby Server(服务端)负责加载模型、执行推理、构造提示(prompt)并对外提供接口;IDE/编辑器扩展(客户端)负责把补全与对话能力嵌入编辑体验,包括流式返回、取消、快捷命令、侧边栏 Chat 视图,以及“对选中代码执行命令”的交互。
官方文档的“Principles”强调端到端优化:IDE 扩展侧会尽量把补全体验做得丝滑(例如支持流式输出与及时取消,并通过自适应缓存提高响应速度),服务端侧也会利用对代码的解析能力来构造更有效的上下文与提示,从而提升补全的相关性与可用性。这种“服务端与客户端协同”的设计决定了 Tabby 更适合团队级落地:服务端集中部署与管控,客户端按 IDE 生态分发与更新。
2. 核心功能:Autocomplete(补全)+ Chat(问答)+ Inline Editing(内联编辑)
以官方 VS Code 扩展文档为例,Tabby 在 IDE 侧的能力主要分为 Autocomplete 与 Chat 两部分,并提供内联编辑能力把“对话式修改”直接落到代码里:
Autocomplete:在你输入过程中提供多行补全,适合写函数骨架、补齐重复性代码、补全常见模式。多行补全相比单行补全更依赖低延迟与稳定的流式输出,因此非常考验服务端推理性能与客户端取消逻辑。
Chat:用于回答通用编程问题,也用于结合当前项目上下文进行解释、建议与讨论。实际使用中,Chat 更适合“解释一段代码在做什么”“某个错误可能原因是什么”“给出替代实现思路”等场景。
Explain / Inline Editing:VS Code 扩展文档中提供了 Tabby: Explain This、Tabby: Start Inline Editing 等命令。你可以选中一段代码后执行“解释”,也可以启动内联编辑(默认快捷键为 Ctrl/Cmd+I)在编辑器中直接发起修改请求,让建议以更贴近编码节奏的方式呈现。
从落地角度看,把“补全”和“对话”分开治理很关键:补全要追求稳定、低延迟与高命中;对话要追求信息密度与可解释性。Tabby 允许你为二者选择不同模型,这也是它在工程实践中更容易调优的原因之一。
3. 自托管部署:官方 Docker Quick Start(含 GPU)
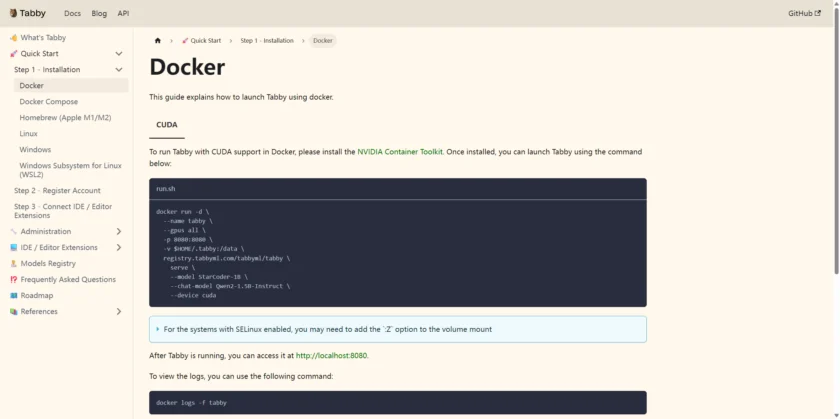
Tabby 官方 Quick Start 提供了多种安装方式,其中 Docker 方案最适合团队快速验证与复现。若要在容器内使用 GPU,官方文档要求先安装 NVIDIA Container Toolkit。随后可用官方示例命令启动 Tabby Server(以下命令与官方 Docker 页面一致):
docker run -d \
--name tabby \
--gpus all \
-p 8080:8080 \
-v $HOME/.tabby:/data \
registry.tabbyml.com/tabbyml/tabby \
serve \
--model StarCoder-1B \
--chat-model Qwen2-1.5B-Instruct \
--device cuda启动后通常通过 http://localhost:8080 访问服务端;排查问题时可使用以下命令查看日志:
docker logs -f tabby建议把“能不能用”的验证拆成两步:
1. 链路验证:服务端是否能稳定启动、端口可访问、账号与 token 是否可用;
2. 体验验证:在你们真实仓库里,补全延迟、取消是否及时、多行补全命中率、Chat/Explain/Inline Editing 是否稳定可用。
Tabby 是开源项目,但自托管并不等于“零成本”:你需要为模型文件存储、GPU/CPU 与内存资源、升级与监控、访问控制与网络连通性负责。这也是团队在从 Copilot 类云服务迁移到自托管路线时最需要提前评估的部分。
4. 编辑器支持:VS Code 与 JetBrains 插件如何接入
Tabby 的服务端可以统一部署,但开发团队往往同时使用多个 IDE。官方文档明确提供了 VS Code 与 IntelliJ Platform(JetBrains 系)等安装与接入说明。
VS Code / VSCodium
官方文档给出的安装方式是在 VS Code 的 Quick Open(Ctrl/Cmd+P)中执行:
ext install TabbyML.vscode-tabby安装完成后,使用命令面板执行 Tabby: Connect to Server...,填入 Tabby Server 的 Endpoint URL 与账号 Token。连接成功后,可以执行 Tabby: Quick Start 走一遍引导,并通过活动栏打开 Chat 视图,或对选中代码执行 Tabby: Explain This,再配合 Tabby: Start Inline Editing 验证内联编辑能力。
IntelliJ Platform(JetBrains IDEs)
官方文档说明 Tabby 的 IntelliJ 插件支持所有 build 版本为 2023.1 或更高的 IntelliJ Platform IDE(例如 IDEA、PyCharm、GoLand、Android Studio 等),并要求安装 Node.js 18.0 或更高版本。典型接入流程如下:
1. 先部署 Tabby Server;2. 从 JetBrains Marketplace 安装 Tabby 插件;3. 安装 Node.js 18+;4. 在插件设置中填写 Server Endpoint(不填时默认 http://localhost:8080)与 Token(如需要),必要时指定 node 可执行文件路径;5. 观察状态栏图标是否显示已连接。
在团队推行时,建议把 Endpoint 与 Token 的分发方式标准化,并明确“开发机到服务端”的网络路径(同机、局域网、VPN、反代网关等)。否则最常见的故障会变成:插件装好了、也显示连接,但补全没有返回或 Chat 不可用,而这往往不是模型问题,而是网络与鉴权路径没有打通。
5. 模型部署与选择:--model 和 --chat-model 的组合策略
Tabby 文档提供了 Models Registry(模型目录),并把模型分为两类用途:
Completion models(--model):用于自动补全,强调低延迟与代码相关性。
Chat models(--chat-model):用于对话能力,文档建议至少使用 1B 规模模型以获得更好的回答质量。
这种拆分非常实用:补全通常更看重“快”和“贴合当前文件”,而对话更看重“解释能力与推理能力”。你可以用更轻量的补全模型确保速度,用更强的对话模型提升问答质量,从而在成本与体验之间做工程化权衡。
官方模型目录还给出了按规模的硬件建议:1B 到 3B 规模模型建议至少使用 NVIDIA T4、10 系或 20 系 GPU,或 Apple Silicon(如 M1);7B 到 13B 规模模型建议使用 NVIDIA V100、A100、30 系或 40 系 GPU。对团队而言,这些建议可以直接变成落地路线:先用小模型跑通链路与工作流,再按预算与质量需求升级。
在模型家族上,Tabby 的模型目录提供了多种 Coding LLM 选项(例如 StarCoder/StarCoder2、CodeLlama、DeepSeekCoder、CodeGemma、CodeQwen、Qwen2.5-Coder、Codestral 等),并提示不同模型存在不同的许可证与取舍。建议优先以官方 Models Registry 的推荐、benchmark 与 leaderboard 作为依据,再结合你们代码语言栈与仓库规模进行试跑对比。
6. 适用人群、定价与成本:开源免费,不等于没有投入
Tabby 是开源项目,源码与部署方式公开;这意味着你通常不需要为“按席位订阅”付费,但需要承担自托管成本。典型成本构成包括:
1. 算力成本:GPU 显存、CPU 与内存直接决定补全延迟与并发能力;
2. 存储与网络:模型文件、缓存与数据目录需要持久化;跨网络访问会带来额外延迟与安全要求;
3. 运维成本:版本升级、监控告警、访问控制、审计与故障排查需要工程投入。
因此 Tabby 更适合以下人群与团队:
1. 对代码与研发数据有合规与内网要求,希望 AI 编程能力落在可审计的环境;
2. 有一定基础设施能力(Docker/K8s、GPU 资源池、统一认证/网关),愿意把 AI 编程助手当作团队平台能力长期维护;
3. 想在 VS Code 与 JetBrains 等多 IDE 之间统一接入方式,同时允许不同项目选择不同模型组合。
如果你更看重“零运维、即开即用”,云端 Copilot 类工具可能更省事;而 Tabby 的优势在于可控性、可替换性与自托管的数据边界,这些往往是团队级需求。
官方来源(建议以此为准)
- https://tabby.tabbyml.com/docs/welcome/
- https://tabby.tabbyml.com/docs/quick-start/installation/docker/
- https://tabby.tabbyml.com/docs/extensions/installation/vscode/
- https://tabby.tabbyml.com/docs/extensions/installation/intellij/
- https://tabby.tabbyml.com/docs/models/
- https://github.com/TabbyML/tabby
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/tabby-ml.html -APPMARK
Replit Agent 是一种 AI 编程助手,旨在通过自然语言提示从零开始创建应用程序。它可以自动化开发环境、编写代码、安装软件包、配置数据库和部署等任务,可以再短时间内快速完成各种编程任务。