


Claude 是美国人工智能初创公司 Anthropic 发布的大型语言模型家族,拥有高级推理、视觉分析、代码生成、多语言处理、多模态等能力,该模型对标 ChatGPT 、 Gemini 等产品。2025 年 2 月 25 日,Anthropic 推出了其首个混合推理模型 Claude 3.7 Sonnet。这个模型的发布不仅标志着技术的重大进步,同时也凸显了 Anthropic 在 AI 研究中的行业地位。相比于传统的大语言模型,Claude 3.7 Sonnet 将推理与生成能力融合,成为市场上唯一的“混合”模型。据透露,Claude 3.7 Sonnet 的训练成本仅为“数千万美元”。
所谓“混合模型”,Claude 3.7 Sonnet 既能提供近乎即时的响应(标准模式,standard),也可以向用户直观展示其长时间的逐步思考过程(扩展思考模式,extended thinking)。API 用户还可以对模型的思考时长进行细粒度控制。简而言之,该模型最大的特点就是用户能控制模型在做出反应前“思考”的时间,这是一项前所未有的技术创新。
基准数据支持了 Anthropic 的雄心壮志。在扩展思考模式下,Claude 3.7 Sonnet 在研究生级推理任务上实现了 78.2% 的准确率,挑战了 OpenAI 的最新模型,并超越了 DeepSeek-R1。
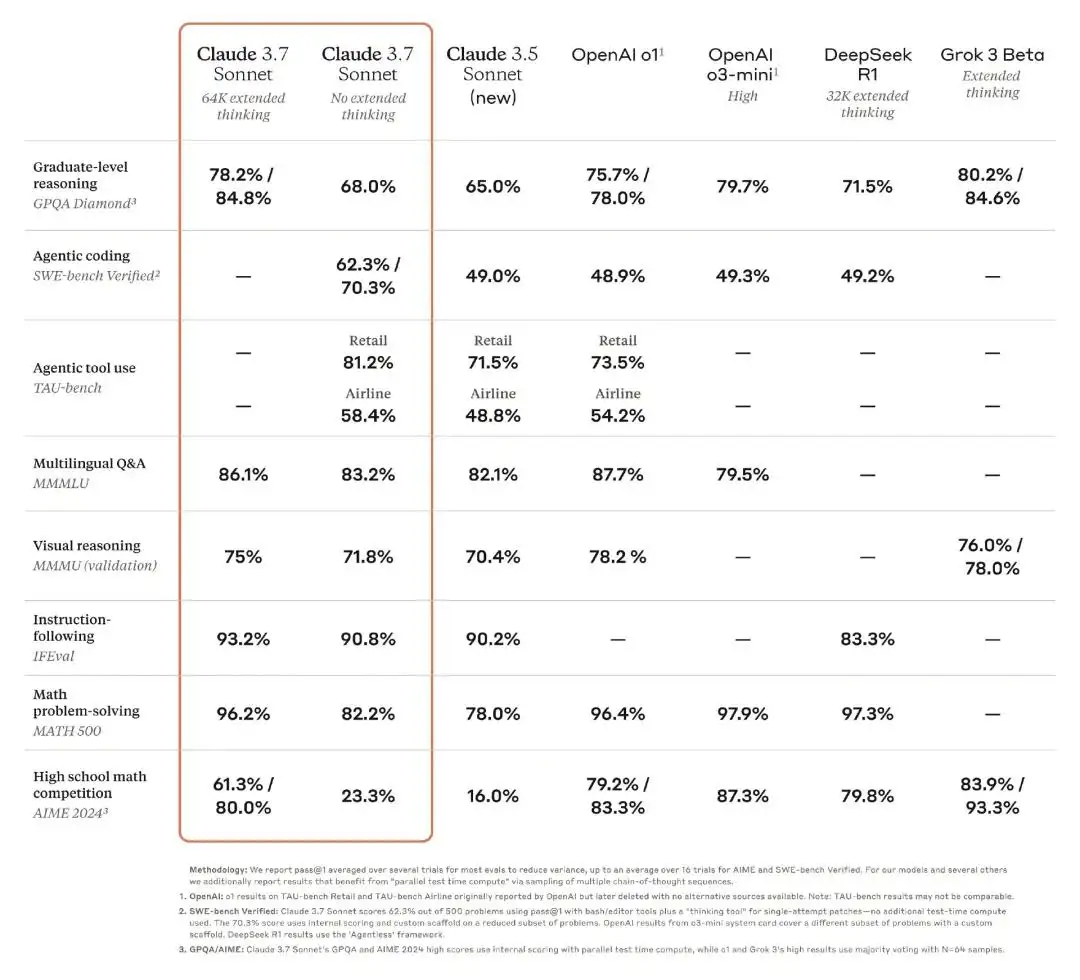
在数学解题(MATH 500)方面,Claude 3.7 Sonnet 64K 扩展思考模型表现优异,及格率较上代模型有了很大提升,但仍不及 OpenAI o1、OpenAI o3-mini High、DeepSeek R1 32K Extended Thinking。
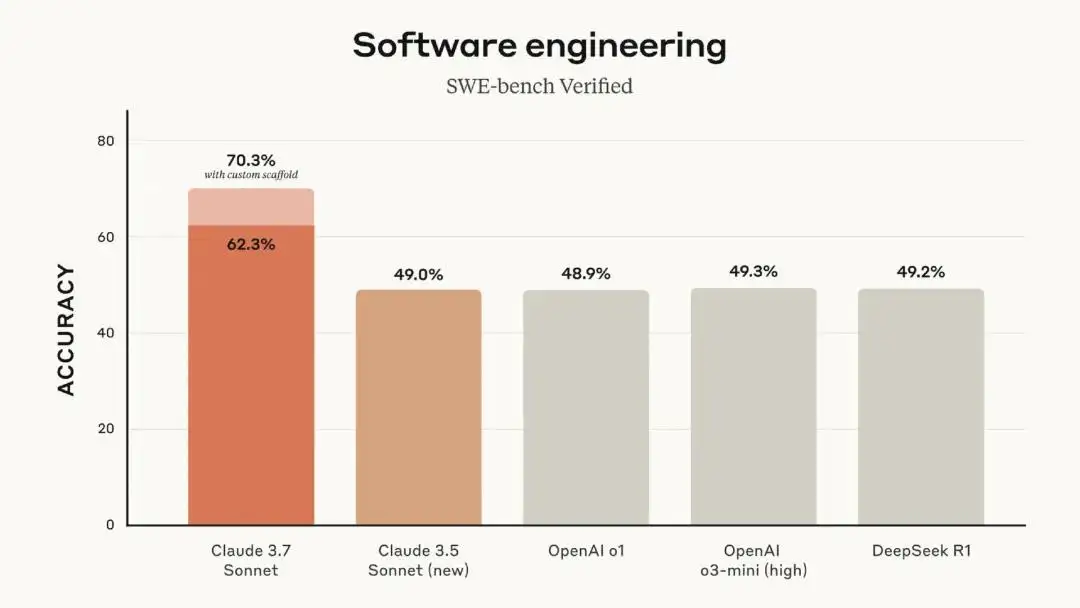
Claude 3.7 Sonnet 在编程领域的表现一如既往、尤为突出。Claude 3.7 Sonnet 只借助 bash 编辑器工具和 “思维工具” 进行单次尝试修补,不额外花时间计算时,通过率能达到 62.3%。要是用上内部评分和自定义框架这些 “特殊手段”,通过率直接涨到 70.3% 。OpenAI 的 o1 模型通过率是 48.9%,o3-mini (high) 通过率为 49.3%,但和 Claude 3.7 Sonnet 比还有一些差距。DeepSeek R1 的通过率是 49.2% ,表现同样不如 Claude 3.7 Sonnet。
在编码方面,Claude 的一个显著优势是,当你通过网页界面使用它时,它不依赖于检索增强生成(RAG)。虽然这会消耗更多的 token,但模型能够直接看到所有内容,从而以更高质量的方式回复。
我想知道,Claude Code 是否也采用了类似的方式,只是改用了文档级别的 RAG?也就是说,如果一个文档是相关的,并且适合上下文窗口,那么整个文档都会被加载进去。如果是这样,那就太棒了!这也意味着将大型代码库拆分为更小的、可管理的文件会变得越来越有意义。
最后,我想对 Claude Sonnet 表达由衷的感谢。在过去的几个月里,它彻底改变了我的工作方式,让我能够完成更多的事情。非常感谢!
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/anthropic-claude.html -APPMARK
Kimi (kimi.moonshot.cn) 是由 Moonshot AI 开发的系列大语言模型和智能 AI 助手,以其超长的上下文窗口和强大的多文件、URL 分析能力而著称。它支持实时网络搜索、多语言,并具备高级推理能力,旨在帮助用户高效地处理和理解大量信息。