

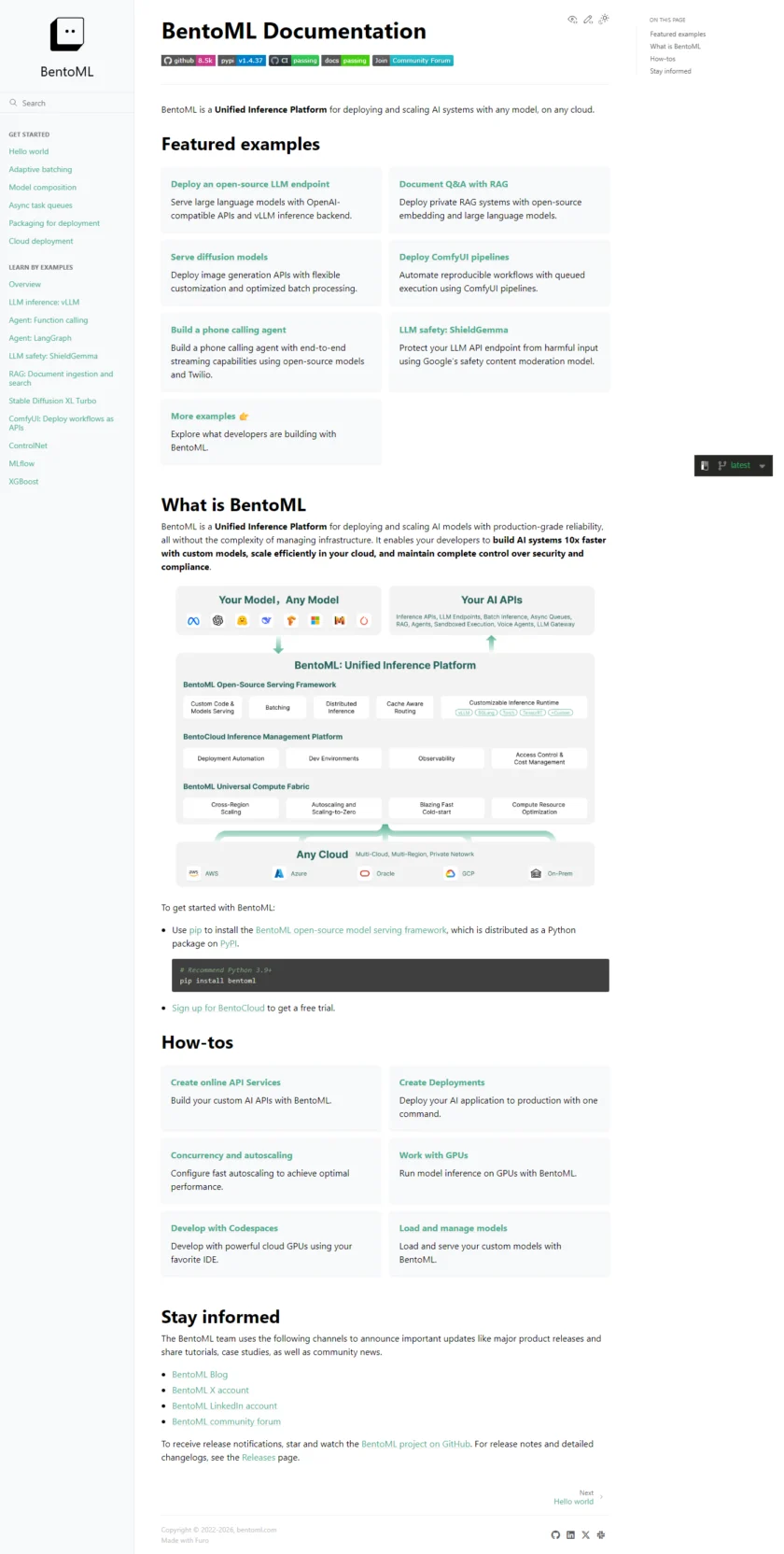
BentoML 是一个开源的模型与 AI 应用服务框架,目标很明确:让你把“模型推理能力”以工程化的方式交付出去。它既能用来构建模型推理 API,也覆盖更偏生产化的形态,比如任务队列、批处理与 LLM 应用服务。在官网的定位语句里,它强调的是“Run Inference at Scale”,也就是把推理从单机脚本提升为可部署、可扩展、可运维的服务。
这是什么产品
如果你把 AI 应用交付过程拆开看,大致会经历三件事:第一,把模型和推理逻辑写成稳定的服务接口;第二,把运行时依赖、模型权重与配置固定下来,避免“在我电脑上能跑”;第三,在不同环境(本地、测试、生产)里一致地运行,并能观察、扩缩容和升级。BentoML 试图把这三件事串成一条更短的路径:从文档的 Hello World 开始,开发者可以用它定义服务(Service)并运行/构建,形成可重复交付的服务形态。
从 GitHub 仓库描述来看,BentoML 的产品边界并不局限在“把模型包一层 HTTP”。它明确提到可以用于构建模型推理 API、任务队列(Job queues)和 LLM 应用,这意味着它既适合经典的模型 Serving,也能覆盖更复杂的异步任务与应用逻辑编排。对团队而言,这种定位比“某个单一模型的推理服务器”更通用,更容易随着模型形态的变化而复用。

核心功能与工作流
BentoML 的核心能力可以从“开发形态”和“交付形态”两条线理解。开发形态上,它提供了一套把推理逻辑组织成服务的方式:你把模型加载、预处理、后处理与接口定义放在服务代码里,并在本地快速启动验证。文档的入门页包含了对 Service、运行与构建流程的讲解,因此它不是要求你先搭一堆基础设施,而是先把服务跑通。
交付形态上,它强调把“代码 + 模型 + 依赖”封装为可部署的产物,这也是它名字里 “Bento” 的隐喻:将运行所需的组件打包在一起,便于在不同环境重复部署。对生产来说,这一点通常比“有没有某个模型优化”更重要,因为团队实际遇到的坑经常来自依赖漂移、镜像不可复现、模型文件路径不一致、环境变量缺失等工程问题。
从实际工作流看,BentoML 更适合以下路径:研发先用文档提供的入门流程快速把服务跑起来,然后逐步把真实模型替换进去;接着把接口层与业务系统(Web 应用、工作流系统、数据管道)对接;最后再把服务放到统一的部署平台上,按环境做参数化配置,并围绕版本升级、灰度和回滚建立规范。BentoML 处在“模型研发”和“应用/平台工程”之间的连接层,目标是让两侧接口更稳定。
如何开始使用
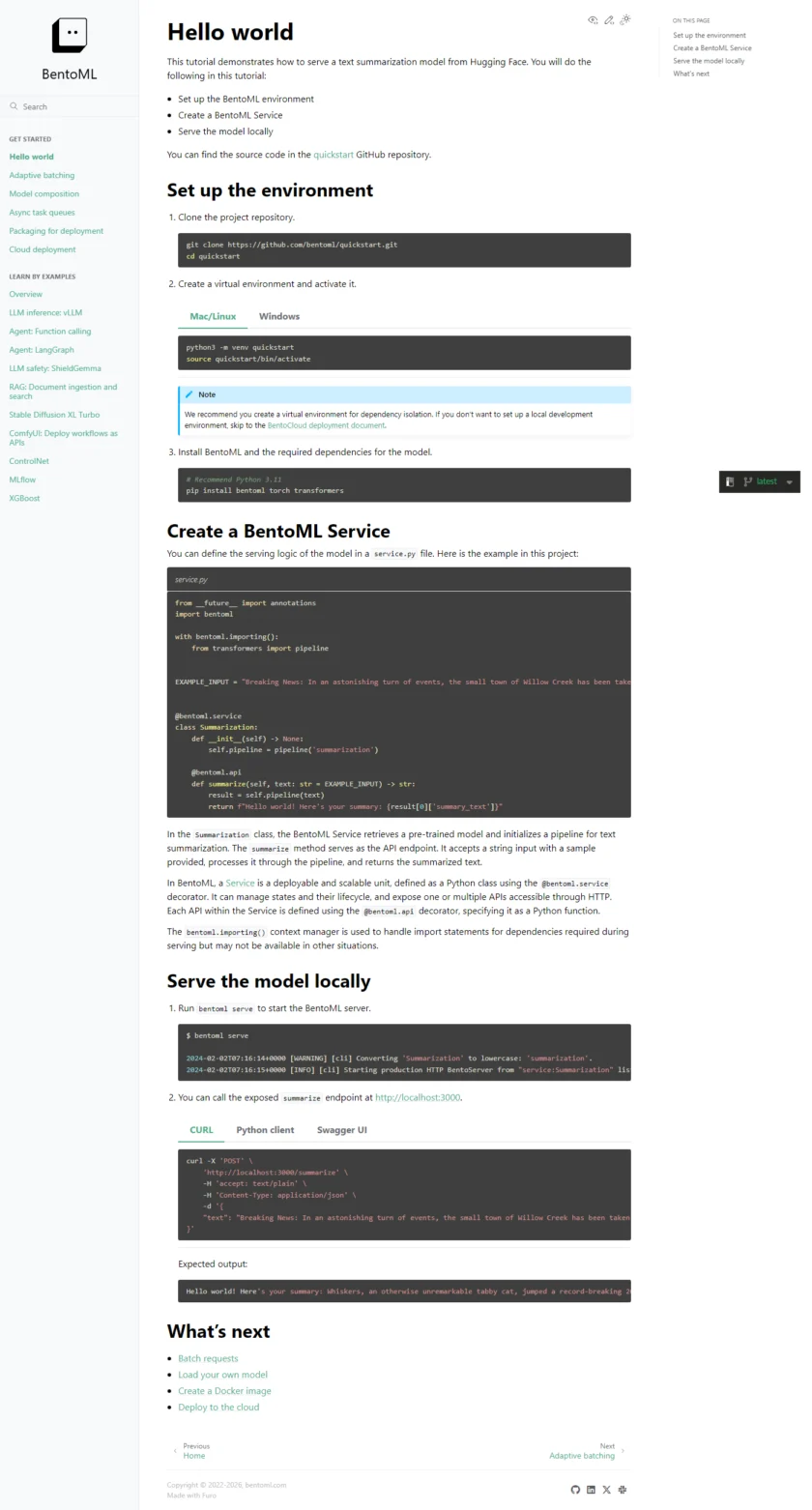
建议用官方文档的 Hello World 作为起点,先把服务从 0 到 1 跑通,再替换为你的真实模型。这样做的好处是:你可以快速确认自己的运行环境、依赖安装、网络访问与端口策略都没问题;同时也能理解 BentoML 的“服务定义方式”和“构建交付方式”各自解决的是什么问题。
如果你已经有一套基于 FastAPI/Flask 的推理接口,或者已有 Docker/Kubernetes 的部署套路,也可以反向评估:BentoML 是否能减少你维护的样板代码(依赖固化、打包结构、服务脚手架),以及在模型不断迭代时是否能降低发布摩擦。它最有价值的场景不是“一次性做完一个 demo”,而是模型会持续更新、服务要长期维护的团队。
在工程落地上,建议从一个明确边界的服务开始:例如单一模型的文本分类或图像分类接口。先把输入输出契约、模型版本管理、依赖封装和日志记录规范立起来,再扩展到更复杂的链路(多模型路由、异步任务、批处理、LLM 应用)。你会更容易在早期就发现系统性问题,比如模型文件存储方式、环境隔离策略、以及发布流程需要的权限与审计能力。
价格与开源状态
BentoML 本体是开源项目。其 GitHub 仓库页面显示采用 Apache-2.0 许可,这意味着在遵守许可条款的前提下,你可以在企业内部或商用场景中使用与二次分发,并将其纳入自己的工程体系中。
在开源之外,BentoML 团队也提供商业化形态(例如托管或企业能力),但这类能力的具体定价与条款需要以官网的最新信息为准。对多数团队而言,更现实的选择是:先用开源 BentoML 解决服务化与交付的工程问题,当部署规模、合规或运维要求提升到一定程度,再评估是否需要引入商业化支持。
适合谁用
BentoML 更适合三类团队。第一类是做产品化 AI 能力的应用团队:你们需要一个稳定的推理服务层,把模型能力暴露给前端、后端或外部客户,同时又不想每个项目都重复造轮子。第二类是平台/基础设施团队:你们负责把模型交付标准化,希望研发同学能用统一的方式交付服务,运维同学能用统一的方法部署、升级与观测。第三类是有多模型、多版本长期迭代需求的团队:服务必须能持续发布而不崩,且要减少环境不一致导致的问题。
它不太适合的情况也很清晰。如果你只是一次性跑一个离线推理脚本,或者模型完全不需要服务化,那么引入服务框架的收益不大。又或者你的组织已经深度绑定某个大型平台(例如强约束的托管 Serving 方案),BentoML 可能更适合作为局部能力补齐,而不是替换所有现有体系。
优势与限制
优势方面,BentoML 的最大价值在于把“服务定义”和“交付打包”两件事放在同一个框架内处理。很多团队在实践中会发现:写一个接口很快,但让它在不同环境里稳定运行很难。BentoML 的设计倾向于把工程化路径铺平,让服务从最初就能走向可部署的形态。其次,它的定位覆盖推理 API、任务队列和 LLM 应用,说明它试图跟上当下 AI 应用形态的变化,而不是只押注单一形态。
限制方面,任何框架都会带来学习成本与约束。团队需要理解它推荐的服务组织方式,并在已有工程体系中做整合(日志、监控、配置、镜像构建、CI/CD 等)。另外,“交付物打包”的抽象是否能完全匹配你们的内部规范,需要通过真实项目验证。如果你们的部署环境高度定制,仍可能需要写额外适配层。
对比与选择
如果你已经用 FastAPI/Flask 直接写推理接口,BentoML 的比较点不在于“能不能提供 HTTP”,而在于是否能让交付更标准、减少重复工程。相比单纯的 Web 框架,它更强调模型服务的工程化交付;相比只解决部署层的方案,它更靠近代码与模型的组织层。与专门的 Serving 系统相比,BentoML 通常更灵活、更偏开发者体验,但你也需要自己决定如何在平台层做统一治理。
选择建议是:把问题具体化。你的痛点如果是“模型交付不一致、依赖难复现、服务模板重复、上线流程摩擦大”,BentoML 往往能提供更直接的改进路径;如果你的痛点是“超大规模推理下的极限性能与硬件编排”,则需要结合你们的推理引擎、加速方案与平台体系综合评估。
结论
BentoML 是一个偏工程化、偏交付的开源框架,适合把模型能力长期以服务形式对外输出的团队。它的核心价值不只是把模型跑起来,而是把模型“稳定地交付出去”。如果你们正在从 PoC 走向生产,或者已经在生产里被交付一致性拖累,BentoML 值得作为标准化服务层的候选方案进行评估。
官方来源
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/bentoml.html -APPMARK
高吞吐、内存高效的大模型推理与服务引擎,支持 OpenAI 兼容 API