

Dolphin 是字节跳动(ByteDance)开源的一款多模态、专注于复杂文档解析的多模态 AI 模型。Dolphin 通过两阶段“分析-解析”机制,先解析页面布局,再并行处理文本、表格、公式等元素,兼顾精准性和效率。Dolphin 完全开源,模型可自主下载,支持输出结构化 JSON 或 Markdown,可运行于端侧。

Dolphin 在多种文档解析任务上表现出色,性能超越了 GPT-4.1、Mistral-OCR 等模型。Dolphin 拥有 322M 参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等,并且能够将解析结果输出为 JSON、Markdown、HTML 等多种格式,便于与不同系统集成。其开源的代码和预训练模型,为开发者提供了极大的便利,也为文档解析领域的发展注入了新的活力。
Dolphin 的核心解析机制
文档图像解析因其复杂交织的元素(如文本段落、图表、公式和表格)而具有挑战性。所以 Dolphin 通过两阶段方法解决这些挑战:
• 阶段 1:通过生成自然阅读顺序中的元素序列,进行全面的页面级布局分析。
• 阶段 2:使用异构锚点和任务特定提示高效并行解析文档元素。
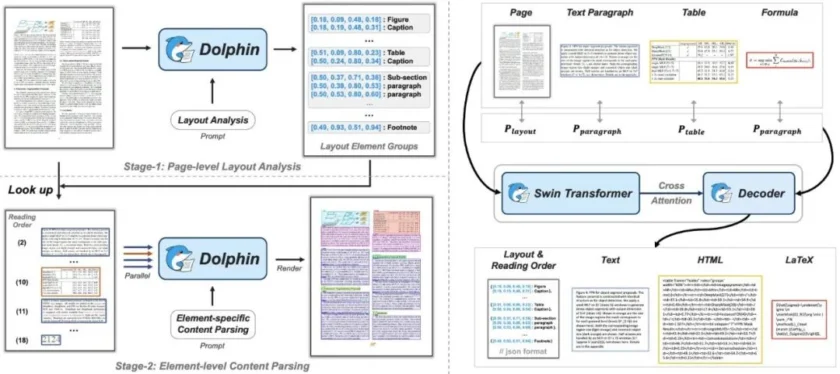
Dolphin 在各种页面级和元素级解析任务中表现出色,同时通过其轻量级架构和并行解析机制确保了卓越的效率。
主要功能
• 页面级解析:支持将整个文档图像解析为结构化格式,输出 JSON(便于数据处理)和 Markdown(便于阅读和编辑)。
• 元素级解析:可以专门对文本、表格、公式等结构做定向识别与分类。
• 自然阅读顺序识别:模拟人类阅读习惯,生成符合逻辑的元素序列,避免传统 OCR 常见的结构混乱问题。
• 并行处理机制:通过轻量架构和并行解析机制,大幅提升处理速度。
• 双推理模式:即页面级解析与元素级解析,非常灵活。
• 在线 Demo 提供:免部署在线体验,可快速体验效果。
应用场景
• 学术论文整理:自动提取标题结构、图表、公式,并转为 Markdown
• 教辅试题解析:精准提取数学题文字与公式,并输出为结构化数据
• 扫描文档数字化:多页批量处理,生成可编辑内容
• 合同/表格结构提取:识别页眉页脚、段落、表格、页码等并输出 JSON
• RAG问答预处理:将结构化内容送入向量库,提升问答召回质量
• AI 读图系统接入:与 LLM 结合,生成更精确、更上下文相关的文档回答或摘要
如何使用
Dolphin 的安装和使用非常友好,官方提供详细文档和 Hugging Face 模型,支持在全平台上使用。首先官方也是专门部署了一套 Gradio 界面,用以体验 Dolphin 的全部功能,用户可以通过访问 http://115.190.42.15:8888/dolphin/ 进行实际操作。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/bytedance-dolphin.html -APPMARK
Google Research & DeepMind 推出的 Google Med-PaLM 2 基于PaLM大模型,是专为医疗问答优化的AI模型。在医学考试问题(如USMLE)中达到专家级准确率,支持多语言医疗信息检索与分析。