

Hamilton 更适合被理解成一套帮助数据团队和 AI 工程团队组织 Python 数据流代码的开源框架,而不是又一个“低代码拖拽 DAG 平台”。它的出发点很务实:很多团队并不缺会跑起来的数据脚本,缺的是一种能让函数之间依赖关系清楚、结果可验证、代码可测试、图谱能自动生成、后续还方便协作演进的结构化方式。Apache Hamilton 试图把这些需求落回到普通 Python 函数上,让开发者不用离开熟悉的语言和工程习惯,就能得到更清晰的数据流定义。
从 GitHub README 和官方文档来看,Hamilton 既服务传统 ETL、特征工程和机器学习流水线,也服务 LLM、RAG 与生成式 AI 工作流。它的优势不在于取代 Airflow 之类的编排器,而在于把“数据变换逻辑如何被拆分、如何组合成 DAG、如何追踪 lineage、如何做校验和观测”这层事情做得更清楚。如果你已经开始把 Python 用在数据产品、特征处理或 AI 应用里,但又觉得脚本越来越难维护,Hamilton 属于值得认真看的那类基础设施。
Hamilton是什么
Hamilton,也就是 Apache Hamilton,是一个开源的 Python 数据流框架。它的核心思想是:用普通的、带类型注解的 Python 函数定义数据变换节点,再由框架自动根据函数参数关系组装出 DAG。这样一来,开发者既保留了 Python 代码的直观性,又能自动获得依赖图、执行计划和一套更适合团队协作的结构。GitHub 首页直接把它描述为帮助数据科学家和工程师定义 modular、self-documenting、testable dataflows 的工具。
这种定位与很多常见工具并不一样。Hamilton 不是以调度中心或大而全平台的方式切入,也不是数据库建模工具。官方文档明确写到,它不是 orchestrator,也不是 feature store;它更像位于数据栈“asset layer”的框架,用来组织表达层的变换代码。换句话说,如果你需要的是“如何把 Python 里的特征计算、指标构造、数据整形、LLM 调用流程写得更像工程而不是临时脚本”,Hamilton 的切入点就会非常清晰。
更重要的是,它并不局限在经典数据工程场景。官方对比页和 README 都明确提到它可以用于 ETL、ML workflows、BI dashboards,也能建模 Generative AI 与 LLM based workflows。对于今天大量在 Python 里拼装检索、提示、上下游转换、结构化输出和评估流程的团队来说,这种“把函数写清楚,再让 DAG 自动显式化”的方式,往往比继续堆 if/else 和 notebook cell 更利于演进。

核心能力与技术结构
Hamilton 的第一项核心能力,是把数据变换代码拆成真正可组合的函数模块。官方文档的架构图写得很直白:Transformations are regular Python functions organized into modules,函数通过参数声明依赖,Driver 再自动组装 FunctionGraph。这样做的直接好处是,节点之间的输入输出关系天然显式,单个函数也更容易做单元测试、替换实现和按环境切换配置,而不是把整段流程都揉进一个大函数或一个难以维护的 notebook。
第二项能力是表达 DAG 的方式足够“代码原生”。GitHub README 强调它的 DAG 定义 built-in coding style,鼓励 modular、easy-to-read、self-documenting、unit testable code。相比很多需要额外 DSL、装饰器套娃或中心化配置的框架,Hamilton 更像是把工程约束长在普通 Python 写法里。你写的依然是函数,但这些函数会自动形成图,并可以随着模块扩展成长成上百乃至上千节点的 pipeline,而不用手工维护一张巨大依赖表。
第三项能力是校验、谱系与可观测性。README 提到可以用 @check_output 做输出属性校验,并结合 SchemaValidator() 跟踪 dataframe-like 对象的 schema。与此同时,Apache Hamilton UI 会自动生成 data catalog、lineage / tracing 和 execution observability,帮助团队查看结果、排查错误和理解执行过程。对于数据与 AI 流程来说,这一点很关键,因为很多问题并不是“代码报不报错”,而是某个中间节点是否悄悄偏离了预期。
第四项能力是兼容性与扩展性。官方文档反复强调它 runs anywhere python runs,并能与 Spark、Ray、DuckDB、Modal、AWS 等执行环境配合,也能通过 function modifiers、adapters 和插件机制与现有技术栈对接。也就是说,Hamilton 不要求你为了引入它而推倒所有基础设施;它更像是一层把数据变换逻辑组织得更清楚的框架,可以接到已有计算后端和运行环境上。
第五项能力则体现在 AI 场景。官方案例与对比页已经把 LLM applications、RAG systems、异步文档处理等场景列进适用范围。对于今天越来越常见的“多个提示步骤、检索组件、结构化处理节点和评估节点互相依赖”的系统而言,Hamilton 的价值在于让这些步骤仍然表现为一张清晰、可追踪、可测试的图,而不是一段越来越难读的 orchestration 脚本。
安装与运行
Hamilton 的安装并不复杂,但它是偏工程化的开源框架,因此默认假设使用者愿意读文档并理解依赖组合。GitHub README 显示基础环境支持 Python 3.8+,如果你需要可视化 DAG,可以安装 pip install "sf-hamilton[visualization]",同时在本机准备 Graphviz。若希望使用官方 UI,还需要安装 ui 与 sdk 依赖,也就是 pip install "sf-hamilton[ui,sdk]"。这说明 Hamilton 的使用体验建立在“按需启用功能模块”上,而不是一键全包。
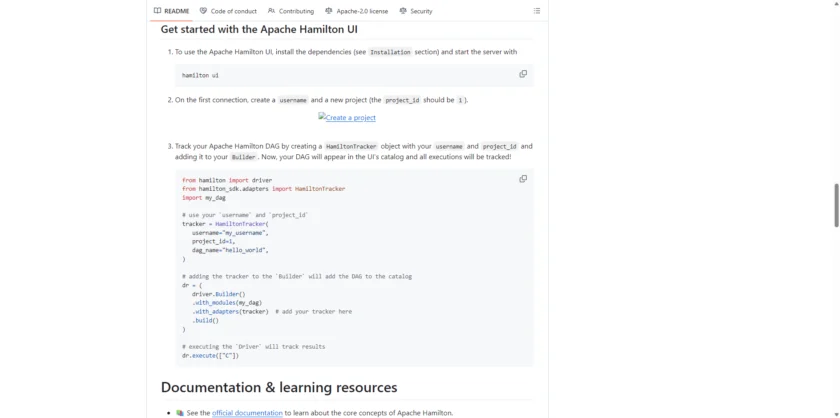
实际运行方式也比较符合 Python 工程师习惯。你先把数据变换拆成模块里的函数,再用 Driver 载入这些模块,指定想要产出的变量,Hamilton 会自动推导出需要计算哪些上游节点并执行。官方示例里,函数 A、B、C 通过参数关系自动形成依赖图;如果接入 UI,则可以通过 hamilton ui 启动本地界面,创建项目后再通过 HamiltonTracker 把执行过程注册进去,之后每次运行都会出现在 catalog 与 trace 里。
对新手来说,比较稳妥的入门路径不是一开始就改造生产流水线,而是挑一段现有 notebook 或脚本里的几步数据变换,先拆成 5 到 10 个函数,看看 DAG 是否更清晰、测试是否更容易写、节点是否更便于复用。官方还提供 tryhamilton.dev、Examples、博客、YouTube 和 Slack 社区,足够支持从“看概念”到“抄一个最小例子跑起来”的过程。只要团队接受 Python-first 的方式,Hamilton 的上手难度并不算高。
不过要注意,Hamilton 不是拖拽平台,也不会替你决定编排、调度、权限或基础设施边界。它擅长的是把数据与 AI 变换逻辑变成结构清晰的代码图。如果团队真正的问题是作业调度、跨任务依赖或平台治理,而不是代码组织本身,那么 Hamilton 往往要和 Airflow、Dagster、Prefect 之类工具配合使用,而不是单独解决所有问题。
许可、版本与社区
Hamilton 在许可上很明确。GitHub README 直接说明它基于 Apache 2.0 License 发布,这意味着它对商业使用、内部修改和再分发都相对友好,适合被企业数据团队与产品团队纳入实际工程体系。对于需要评估合规和二次开发边界的团队来说,Apache 2.0 往往比更苛刻的 copyleft 许可证更容易落地。
版本与生态方面,Hamilton 不是刚冒出来的实验仓库。README 提到它最早起源于 Stitch Fix,之后由原始作者继续推进,并且从 2019 年起就在真实生产场景中被使用。官方同时维持 GitHub 仓库、文档站、Examples、博客、YouTube 以及 Slack 社区,这意味着它的学习与排障资源比较完整,不至于只有一个 README 供你自己摸索。
从社区信号看,Hamilton 的强项并不是“营销很热闹”,而是面向认真做数据与 AI 工程的人提供一套比较稳定的工程方法。官方展示了多家公司和组织的使用案例,也把贡献指南、开发者环境、社区沟通入口公开给外部开发者。对一个基础框架来说,这种持续维护和生态配套通常比一时的明星话题更值得重视。
适合谁
Hamilton 最适合已经在 Python 里处理数据流、特征工程、模型输入输出或 LLM 工作流的团队。典型用户包括数据工程师、机器学习工程师、平台工程师,以及需要把 notebook 原型沉淀成可维护代码的数据科学团队。如果你已经感受到“脚本能跑,但图谱不清楚、函数难复用、变更不敢改、排查节点代价高”,Hamilton 会非常契合。
它也适合那些正在做 RAG、检索增强、结构化抽取、多步骤提示链或模型评估流程的 AI 工程团队。因为这类系统在规模变大后,本质上同样会面临依赖关系复杂、输出质量要校验、执行过程要追踪的问题。Hamilton 把这些问题收敛到一张明确的函数图上,比继续拼接大量临时脚本更容易长期维护。
反过来说,如果你的团队更希望要一个全托管平台、零代码界面,或者你要表达的系统里大量存在循环、条件分支和 agent 式状态机,那么 Hamilton 可能不是唯一答案。官方自己也提示过,如果你的重点是 loops 或 conditional logic,可以看看 Burr 等更适合那类模式的库。因此选型时要先弄清楚:你真正缺的是代码结构、可视化和测试能力,还是更高层的运行时控制。
优势与限制
Hamilton 的最大优势,是它把工程质量要求直接嵌进了 Python 数据流定义方式里。函数就是节点,参数就是依赖,模块就是组合单位,这让代码可读性和 DAG 显式性天然绑在一起。相比把业务逻辑散落在 notebook、SQL、平台配置和胶水脚本里,这种方式更容易被团队共同维护,也更容易在代码评审时讨论“这一步是否合理”。
第二个优势是它在可观测性与演化上的投入很实用。无论是自动生成 DAG、做 schema 校验,还是通过 Hamilton UI 提供 lineage、execution tracking 和 catalog,目标都很明确:让团队在流程变复杂后仍然能看见系统是怎么跑的。对于数据产品和 AI 应用来说,可观察性越早建立,后面改动就越不容易失控。
它的限制同样明显。首先,Hamilton 不是全能编排器,不能指望它单独解决调度、权限、资源管理和所有运行时逻辑。其次,它虽然降低了数据流代码的混乱程度,但并不会自动消除团队本身对 Python 工程实践的要求。如果团队不写测试、不做模块边界管理、不愿意维护类型与命名规范,那么引入 Hamilton 也只能部分缓解问题。
另外,对于特别偏交互式、事件驱动或状态机式的 agent 场景,Hamilton 可能不是最自然的表达工具。它在“清晰的数据变换图”这个问题上非常强,但如果流程逻辑核心是循环、多轮决策和分支控制,就需要结合别的框架。理解这一点,反而能帮助团队把 Hamilton 用在最擅长的层面,而不是错误期待它包办整套系统。
结论
如果你想为 Python 数据流、特征工程或 LLM 工作流建立一套更模块化、可测试、可追踪的结构,Hamilton 是非常值得评估的开源框架。它不靠复杂平台抽象取胜,而是把普通函数提升为清晰的数据流节点,让工程团队在保留 Python 灵活性的同时,获得 DAG、lineage 和执行观测带来的秩序感。
对已经有一定工程基础的团队来说,Hamilton 的价值往往会随着流程复杂度增长而越来越明显;对只是想找一个全托管编排平台的人,它则未必是最直接的选择。把它视为“数据与 AI 变换逻辑的结构化层”,而不是万能 orchestration 平台,通常能得到最稳妥的判断。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/hamilton.html -APPMARK
面向生产环境的多智能体开发框架,支持 Python/TypeScript、工具、RAG 与工作流编排