

什么是 MedRAG
MedRAG (Medical Retrieval-Augmented Generation) 是一个专门为医疗领域设计的检索增强生成(Retrieval-Augmented Generation, RAG)框架。它旨在通过结合从医学知识库或电子健康记录(Electronic Health Records, EHR)中检索到的相关信息与大型语言模型(Large Language Models, LLMs)的生成能力,从而提升医疗诊断和治疗建议的准确性和可靠性。MedRAG 的核心思想是利用外部医学知识来增强 LLMs 的推理能力,尤其是在疾病表现相似、难以区分的情况下,从而减少误诊率,并为医疗从业人员提供更精准的决策支持。
MedRAG 的功能
MedRAG 框架具备以下关键功能:
- 知识图谱增强推理: MedRAG 的核心在于整合了一个全面的四层分层诊断知识图谱(Diagnostic Knowledge Graph, KG),该知识图谱包含了各种疾病的关键诊断差异。通过利用知识图谱的推理能力,MedRAG 能够提供更具体和个性化的诊断见解。
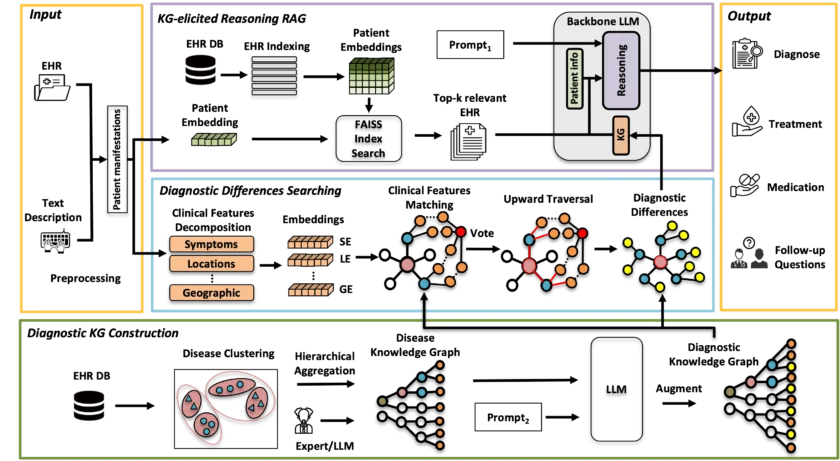
- 电子健康记录检索: MedRAG 能够从 EHR 数据库中检索与患者病情相似的记录,并将这些信息动态地与知识图谱中的诊断差异相结合,为 LLM 提供更丰富的上下文信息。
- 多层次表现匹配: MedRAG 能够将患者的临床表现分解为症状和部位等特征,并在诊断知识图谱内进行多层次的匹配和向上遍历,从而识别关键的诊断差异。
- 主动生成后续问题: 除了提供诊断和治疗建议外,MedRAG 还能够根据需要主动生成相关的后续诊断问题,以进一步澄清模糊的患者信息,从而提高诊断的准确性。
- 支持多种大型语言模型: MedRAG 被设计为能够与多种 LLMs 集成,包括开源和闭源模型,例如 OpenAI 的 GPT-3.5 和 GPT-4,以及 Meta 的 Llama 系列等。这为用户提供了灵活性,可以根据自己的需求选择合适的 LLM 作为 MedRAG 的推理引擎。
- 在真实世界和公共数据集上进行评估: MedRAG 在公共数据集 DDXPlus 和合作医院提供的私人慢性疼痛诊断数据集(CPDD)上进行了评估,实验结果表明,与现有的 RAG 方法相比,MedRAG 在降低误诊率方面表现更优。
- 加速信息检索: MedRAG 提供了通过缓存语料库和使用 HNSW 索引等技术来加速信息检索的功能,从而提高系统的响应速度。
- 支持多种医学知识来源: MedRAG 可以利用来自 PubMed、StatPearls、医学教科书和维基百科等多个不同来源的医学知识作为其语料库。
如何使用/快速开始
要开始使用 MedRAG 工具包,您可以按照以下步骤进行操作:
- 安装依赖: 首先,您需要安装与您的系统 CUDA 版本兼容的 PyTorch,然后使用 pip 安装 MedRAG 的其余依赖项:
pip install -r requirements.txt对于使用 GPT-3.5 或 GPT-4 等模型,您可能需要一个 OpenAI API 密钥,并将其添加到
src/config.py文件中。首次下载和加载语料库可能需要安装 Git-lfs。如果需要使用 BM25 检索器,还需要安装 Java。 - 配置 API 令牌: 如果您计划使用 OpenAI 或 Hugging Face 的模型,您需要替换
authentication.py文件中的占位符,填入您自己的 API 令牌。 - 初始化 MedRAG 对象: 在您的 Python 代码中,导入
MedRAG类并创建一个实例。您可以指定要使用的 LLM 名称、是否启用 RAG、检索器名称和语料库名称等参数。例如:from medrag import MedRAG medrag = MedRAG(llm_name="OpenAI/gpt-3.5-turbo-16k", rag=True, retriever_name="MedCPT", corpus_name="Textbooks") - 提出问题: 您可以向 MedRAG 对象提出医学相关的问题。例如:
question = "A lesion causing compression of the facial nerve at the stylomastoid foramen will cause ipsilateral" options = { "A": "paralysis of the facial muscles.", "B": "paralysis of the facial muscles and loss of taste.", "C": "paralysis of the facial muscles, loss of taste and lacrimation.", "D": "paralysis of the facial muscles, loss of taste, lacrimation and hyperacusis." } answer, snippets, scores = medrag.answer(question, options) - 获取答案和相关信息:
medrag.answer()方法将返回答案、相关的文本片段(snippets)以及它们的分数。 - 加速检索(可选): 您可以通过在初始化
MedRAG对象时设置corpus_cache=True来将语料库缓存到内存中,以加快后续的信息检索速度。对于密集检索器,首次初始化时设置HNSW=True可以进一步加速索引构建。
MedRAG 提供了一个强大的工具,可以帮助医疗专业人员更准确地进行诊断和制定治疗方案。通过结合知识图谱推理和信息检索,它有望在医疗决策支持领域发挥重要作用。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/medrag.html -APPMARK
Neurite 是一个开源框架,用于构建响应式的数据流网络。它提供了一种声明式的方式来定义数据处理流程,支持可组合、可扩展的网络构建。