

Whisper 是由 OpenAI 推出的开源多语言语音识别模型,擅长高精度转写和翻译,适合语音转文本、会议记录等场景。Whisper 最早由 OpenAI 于 2022 年 12 月发布,虽然论文名字是Robust Speech Recognition via Large-Scale Weak Supervision,但不只是具有语音识别能力,还具备语音活性检测(VAD)、声纹识别、语音翻译(其他语种语音到英语的翻译)等能力。
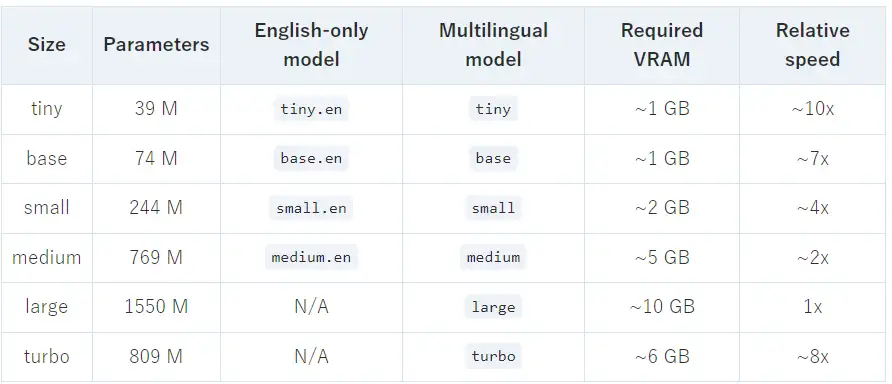
Whispert 已迭代更新至 large-v3-turbo ,Whisper large-v3-turbo 语音转录模型是 large-v3 的优化版本,并且只有 4 层解码器层(Decoder Layers),作为对比 large-v3 共有 32 层。模型共有 8.09 亿参数,比 7.69 亿参数的 medium 模型稍大,不过比 15.5 亿参数的 large 模型小很多,并且所需的 VRAM 为 6 GB,而 large 模型需要 10 GB 。
Whisper相关资源
- Blog:Introducing Whisper
- Paper:https://cdn.openai.com/papers/whisper.pdf
- Model: https://huggingface.co/openai/whisper-large-v2
- Belle-whisper:BELLE-2/Belle-whisper-large-v2-zh · Hugging Face (增强中文识别能力的开源模型)
- Belle-distilwhisper: BELLE-2/Belle-distilwhisper-large-v2-zh · Hugging Face (蒸馏模型基础上增加中文识别能力)
Whisper 特点
Whisper 是端到端的语音系统,相比于之前的端到端语音识别,其特点主要是:
- 多语种:英语为主,支持 99 种语言,包括中文。
- 多任务:语音识别为主,支持 VAD、语种识别、说话人日志、语音翻译、对齐等。
- 数据量:68 万小时语音数据用于训练,从公开数据集或者网络上获取的多种语言语音数据,远超之前语音识别几百、几千、最多 1 万小时的数据量。
- 鲁棒性:主要还是源于海量的训练数据,并在语音数据上进行了常见的增强操作,例如变速、加噪、谱增强等。
- 多模型:提供了从 tiny 到 large,从小到大的五种规格模型,适合不同场景。
Whisper-large-v3-turbo 是一款专为多语言语音转录设计的先进模型,其核心功能是将音频内容快速转化为文本,适用于从日常对话到专业场景的广泛需求。
如何使用
有多种方式可以使用 Whisper 系列模型进行语音转录,其中,最为推荐的方法如下:
1.登录 HuggingFace,使用 Whisper-web(一个直接在浏览器中进行ML语音识别的开源项目)项目

2.下载模型文件,离线使用 Whisper.cpp 应用
3.本地私有化部署
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/openai-whisper-2.html -APPMARK
Orpheus TTS 是 Canopy Labs 开发的一款开源文本转语音系统,基于 Llama 架构,旨在生成高质量、富有表现力的类人语音。它具备零样本语音克隆、引导式情感和语调控制以及低延迟等先进功能,适用于各种需要自然语音合成的应用场景,并提供了详细的安装和使用指南以及丰富的示例代码。