


什么是 Step-Audio
Step-Audio 是阶跃星辰团队推出的首个产品级的开源语音交互模型,能根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,能和用户自然地进行高质量对话。Step-Audio 不是单个模型,而是模型系列的统称,其中包括 130 亿参数的 Step-Audio-Chat、30 亿参数的 Step-Audio-TTS-3B 和音频预处理小助手 Step-Audio-Tokenizer。
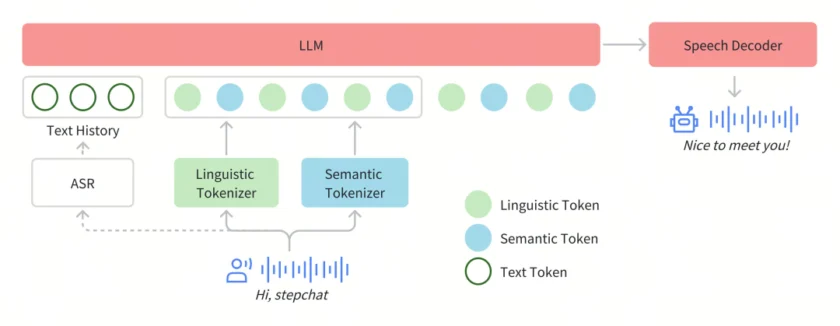
在 Step-Audio 系统中,音频流采用 Linguistic tokenizer(码率 16.7 Hz,码本大小 1024)与 Semantice tokenizer(码率 25 Hz,码本大小 4096)并行的双码本编码器方案,双码本在排列上使用了 2:3 时序交错策略。通过音频语境化持续预训练和任务定向微调强化了 130B 参数量的基础模型(Step-1),最终构建了强大的跨模态语音理解能力。为了实现实时音频生成,系统采用了混合语音解码器,结合流匹配(flow matching)与神经声码技术。
Step-Audio的特点和应用
Step-Audio 包括如下 4 大技术亮点:
- 1300 亿多模态理解生成一体化:单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型
Step-Audio-Chat 版本。 - 高效合成数据链路 :Step-Audio 突破传统 TTS 对人工采集数据的依赖,通过千亿模型的克隆和编辑能力,生成高质量的合成音频数据,实现 “合成数据生成与模型训练的循环迭代” 框架,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。
- 精细语音控制:支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
- 扩展工具调用:通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
Step-Audio 适用的应用场景包括:
- 智能客服:提供个性化、情绪化服务,提升用户体验。
- 有声阅读:生成有情感朗读,增强听书沉浸感。
- 音视频创作:自动生成视频配音或动画角色配音。
- 游戏NPC:为游戏角色提供自然流畅语音交互。
- 会议记录:实时转语音为文本,提供语音反馈。
- 教育辅助:个性化教学助手,调整教学风格语气。
如何使用
- 获取代码与依赖:
访问官方GitHub仓库(https://github.com/stepfun-ai/Step-Audio)下载模型代码及一键安装包。 - 部署环境:
安装Python 3.10及以上版本,通过pip安装依赖库(如 PyTorch、Transformers),并配置 GPU 加速环境以提升生成效率。 - 基础语音生成:
使用预训练模型加载脚本,输入文本指令(如“以欢快的语气用四川话朗读以下内容”),即可生成对应语音文件。 - 进阶功能开发:
- 音色克隆:上传目标音色的短样本音频,通过微调模块训练个性化语音模型。
- 实时交互:调用 API 接口集成至应用程序,结合 WebSocket 实现低延迟对话。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/step-audio.html -APPMARK
Coqui TTS 是 Coqui-ai 团队推出的一款基于深度学习的文本转语音项目。 它以其开源性和强大功能在 TTS 领域崭露头角。