

什么是 Unsloth
Unsloth AI 是一个开源的 Python 库,专门为加速和优化大型语言模型(Large Language Models, LLMs)的微调过程而设计。其核心目标是在保持甚至提高模型准确性的前提下,显著减少内存使用并提升训练速度,尤其是在消费级 NVIDIA GPU 上。Unsloth 通过手动推导计算密集型数学步骤并手写 GPU 内核,实现了在不改变硬件配置的情况下大幅提升训练效率。相较于传统的微调方法,Unsloth 声称能够实现高达 30 倍的训练速度提升和高达 90% 的内存占用减少,同时还能提高模型准确性达 30%。Unsloth 支持包括 Mistral、Gemma、Llama 1、Llama 2 和 Llama 3 等多种流行的 LLM 架构,并支持包括 4 位和 16 位 LoRA(Low-Rank Adaptation)微调技术,使得更多开发者和研究人员能够在资源有限的环境下高效地进行 LLM 的定制和优化。
Unsloth 的功能
Unsloth 提供了多项关键功能,使其在 LLM 微调领域具有显著的优势:
- 极速微调: Unsloth 通过优化的 GPU 内核和手动反向传播引擎,实现了比 Flash Attention 2 (FA2) 快 2 倍到 32 倍的训练速度,具体加速效果取决于 GPU 的数量和型号。
- 超低内存占用: Unsloth 显著降低了微调过程中的内存需求,声称比标准方法减少高达 90% 的内存使用,使得在单张消费级 GPU 上微调大型模型成为可能。
- 零精度损失: Unsloth 强调其优化方法不会以牺牲模型准确性为代价,所有计算都是精确的,没有使用近似方法。
- 广泛的硬件支持: Unsloth 支持自 2018 年以来发布的大部分 NVIDIA GPU,包括 Tesla T4 到 H100 等型号,并且正在努力扩展到 AMD 和 Intel GPU 的支持。
- LoRA 和 QLoRA 支持: Unsloth 支持 4 位和 16 位的 QLoRA(Quantization-aware Low-Rank Adaptation)和 LoRA 微调技术,进一步降低了内存需求。
- 简单的 API: Unsloth 提供了一个简洁易用的 API,可以轻松集成到现有的 Transformers 工作流程中,简化了 LLM 微调的复杂性。
- Transformer 集成: Unsloth 构建在流行的 Transformers 库之上,可以充分利用 Hugging Face 生态系统的强大功能。
- 支持多种模型架构: Unsloth 支持多种流行的 LLM 架构,包括 Mistral、Gemma、Llama 系列、Qwen 等。
- 保存为 vLLM 和 GGUF 格式: Unsloth 允许用户一键合并、转换量化模型并将其推送到 Hugging Face Hub。
- 长上下文推理支持: Unsloth 引入了长上下文推理(GRPO)技术,可以在仅 5GB 显存的情况下训练具有推理能力的 LLM。
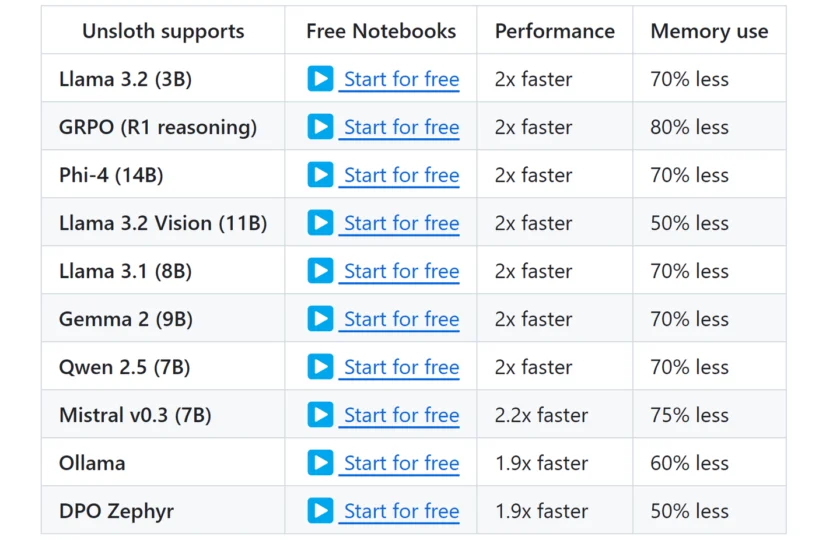
Unsloth 极大加速了模型微调的速度,同时降低显存占用。来看一下 Unsloth 惊人的加速和显存节省:
如何使用/快速开始
要开始使用 Unsloth 微调 LLM,您可以按照以下步骤进行操作:
- 安装 Unsloth: 您可以使用 pip 命令安装 Unsloth 库:
pip install unsloth - 安装依赖(Windows 用户): 如果您在 Windows 上运行 Unsloth,可能需要安装 NVIDIA 视频驱动、Visual Studio C++、CUDA Toolkit 和与您的 CUDA 驱动兼容的 PyTorch 版本。详细的安装说明可以在 Unsloth 的 GitHub 仓库中找到。
- 加载模型和分词器: 使用 Unsloth 提供的
FastLanguageModel类加载您想要微调的预训练模型和对应的分词器。例如,加载 Llama 3.1 模型:from unsloth import FastLanguageModel import torch max_seq_length = 2048 dtype = None # 可以设置为 torch.float16 或 torch.bfloat16 以进一步减少内存使用 model, tokenizer = FastLanguageModel.from_pretrained( model_name="unsloth/Meta-Llama-3.1-8B-bnb-4bit", # 或者其他支持的模型 max_seq_length=max_seq_length, dtype=dtype ) - 加载和处理数据集: 使用 Hugging Face 的
datasets库加载您的微调数据集,并进行必要的预处理,例如将文本转换为模型可以理解的格式。 - 设置模型参数: 根据您的需求配置模型的训练参数,例如学习率、训练轮数等。
- 开始模型训练: 使用 Unsloth 提供的训练工具或结合 Hugging Face 的
Trainer类进行模型微调。Unsloth 提供了优化的训练循环,可以显著提高训练速度和效率。例如,可以使用SFTTrainer进行监督微调:from transformers import TrainingArguments from trl import SFTTrainer training_arguments = TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, warmup_steps=100, max_steps=1000, learning_rate=2e-4, fp16=True, # 如果您的 GPU 支持,可以使用混合精度训练 logging_dir="./logs", output_dir="./output", optim="paged_adamw_32bit", # 推荐的优化器 ) trainer = SFTTrainer( model=model, train_dataset=train_dataset, tokenizer=tokenizer, args=training_arguments, ) trainer.train() - 测试和保存模型: 微调完成后,您可以测试模型的性能,并将模型和分词器保存到本地或上传到 Hugging Face Hub。
Unsloth 提供了丰富的文档和示例代码,您可以在其 GitHub 仓库(https://github.com/unslothai/unsloth)和官方网站(https://unsloth.ai/)上找到更多详细的使用指南和教程。Unsloth 还提供了免费的 Google Colab 和 Kaggle Notebooks,您可以直接在这些平台上体验 Unsloth 的快速微调功能。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/unsloth.html -APPMARK
PEFT (Parameter-Efficient Fine-Tuning) 是 Hugging Face 提供的一个库,旨在通过多种参数高效的微调技术,帮助开发者以低成本的方式将预训练好的大型语言模型适配到各种下游任务中,显著降低计算和存储需求。