

AI-Researcher 是一个基于大型语言模型(LLM)的自动化科研工具。AI-Researcher 基于多模态数据集成、LLM 智能代理和自动化实验验证等技术,实现科研任务的高效处理,其核心功能包括支持文献综述、算法设计、实验验证和论文撰写等全流程自动化。

AI-Researcher 是什么?
AI-Researcher 是香港大学数据科学实验室推出的开源自动化科研工具,旨在通过大型语言模型(LLM)代理实现从研究想法到论文发表的全流程自动化。该工具支持用户在两种模式下操作:一是提供详细的研究想法描述,系统据此生成实现策略;二是提供参考文献,系统自主生成创新想法并实施。
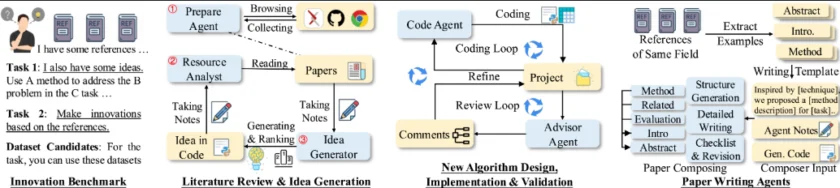
AI-Researcher 集成了文献综述、想法生成、算法设计与验证、结果分析和论文撰写等核心功能,支持多领域研究,并基于开源的基准测试套件评估研究质量。无论是计算机视觉、自然语言处理,还是数据挖掘等领域,AI Researcher 都能提供高效的科研支持。
AI-Researcher 的主要功能
- 文献综述:系统自动收集和分析特定领域的现有研究文献,基于检索学术数据库(如 arXiv、IEEE Xplore 等)和代码平台(如 GitHub、Hugging Face)获取高质量的研究资源。
- 算法验证与优化:自动进行实验设计、执行和结果分析,评估算法的性能,根据反馈进行优化,确保算法的有效性和可靠性。
- 论文撰写:自动生成完整的学术论文,包括研究背景、方法、实验结果和讨论等内容。
- 多领域支持与基准测试:支持计算机视觉、自然语言处理、数据挖掘等多个领域的研究,提供标准化的基准测试框架,用于评估研究质量和创新性。
AI-Researcher 的技术原理
- 多模态数据集成与处理:系统基于自动化工具从学术数据库和代码平台收集文献、代码和数据集,利用自然语言处理(NLP)技术对文本内容进行解析和分析,提取关键信息。
- 基于 LLM 的智能代理:基于大型语言模型(LLM)作为核心驱动,利用预训练模型(如 OpenAI 的 GPT 或 DeepSeek 的模型)生成高质量的文本内容,包括研究想法、算法设计和论文撰写。
- 自动化实验与验证:系统基于容器化技术(如 Docker)和自动化脚本,实现算法的快速部署和实验执行。系统自动设计实验流程、收集结果,基于机器学习技术对结果进行分析和优化。
- 多级任务处理与模块化设计:支持两种任务级别:用户提供详细想法(Level 1)和仅提供参考文献(Level 2)。系统根据任务级别调用不同的模块,实现从想法生成到论文撰写的全流程自动化。
如何使用 AI-Researcher
AI-Researcher 是一个全自动化科学发现系统,它通过先进的 AI 代理技术重塑传统研究范式,为研究人员提供从概念到发表的无缝支持。下面将为您详细介绍如何运行 AI-Researcher,并结合具体示例演示其主要功能。
AI 安装
git clone https://github.com/HKUDS/AI-Researcher.git cd AI-Researcher pip install -e .
Docker 安装
docker pull tjbtech1/paperagent:latest
设置 API Key
根据提供的 '.env.template' 文件创建一个环境变量文件。在此文件中,设置你打算使用的 LLMs 的 API 键。请注意,并非所有 LLM API 键都是必需的——只需包含与你的需求相关的键。
OPENAI_API_KEY= DEEPSEEK_API_KEY= ANTHROPIC_API_KEY= GEMINI_API_KEY= HUGGINGFACE_API_KEY= GROQ_API_KEY= XAI_API_KEY=
示例 :矢量量化(Vector Quantized)
Input:Prompt/输入:提示
I have some reference papers, please implement the following idea with these papers(我有一些参考论文,请用这些论文实现以下想法)
1. 提出的模型旨在通过解决非可微矢量量化层的梯度传播问题,提升矢量量化变分自编码器(VQ-VAE)的性能。 2. 核心方法包括: - 旋转和缩放变换:调整编码器输出以对齐最近的码本向量,而不改变前向传播输出。 - 梯度传播方法:确保梯度从解码器流向编码器,同时保持梯度与码本向量之间的角度。 - 码本管理:通过连接编码器输出与码本向量的关系,避免码本崩溃并提高利用率。
Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks 理顺直通估计器:克服向量量化网络中的优化挑战 Estimating or propagating gradients through stochastic neurons for conditional computation 通过随机神经元估计或传播梯度以进行条件计算 High-resolution image synthesis with latent diffusion models 使用潜在扩散模型的高分辨率图像合成 Finite scalar quantization: Vq-vae made simple 有限标量量化:Vq-vae 简化版 Elements of information theory 信息论的元素 Vector-quantized image modeling with improved vqgan 带有改进的 VQGAN 的向量量化图像建模 Uvim: A unified modeling approach for vision with learned guiding codes Uvim:一种使用学习引导代码的统一视觉建模方法 Auto-encoding variational bayes 自动编码变分贝叶斯 Categorical reparameterization with gumbel-softmax 类别重参数化与 gumbel-softmax
运行命令
current_dir=$(dirname "$(readlink -f "$0")")
cd $current_dir
export DOCKER_WORKPLACE_NAME=workplace_paper
export BASE_IMAGES=tjbtech1/paperagent:latest
export COMPLETION_MODEL=claude-3-5-sonnet-20241022
export CHEEP_MODEL=claude-3-5-haiku-20241022
category=vq
instance_id=one_layer_vq
export GPUS='"device=0,1"'
python run_infer_plan.py --instance_path ../benchmark/final/${category}/${instance_id}.json \
--container_name paper_eval --task_level task1 --model $COMPLETION_MODEL \
--workplace_name workplace --cache_path cache --port 12372 --max_iter_times 0 --category ${category}
运行完成后,系统将生成一份完整的论文(PDF 文件)以及研究工作区的代码实现。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/hkuds-ai-researcher.html -APPMARK
Browser Use 是一个 Python 库,旨在连接 AI 代理与 Web 浏览器,使其能够控制浏览器并执行各种在线任务自动化操作。该库支持复杂的任务处理、数据收集和模型评估,为开发能够与 Web 应用程序无缝集成的 AI 代理提供了强大的工具。