


什么是 Canopy
Canopy 是由 Pinecone 开发的一个开源框架,专门用于简化构建检索增强生成(Retrieval-Augmented Generation, RAG)应用程序的过程。在人工智能领域,RAG 是一种强大的技术,它通过在生成文本之前从外部知识库检索相关信息,来增强大型语言模型(LLMs)的知识和生成能力。
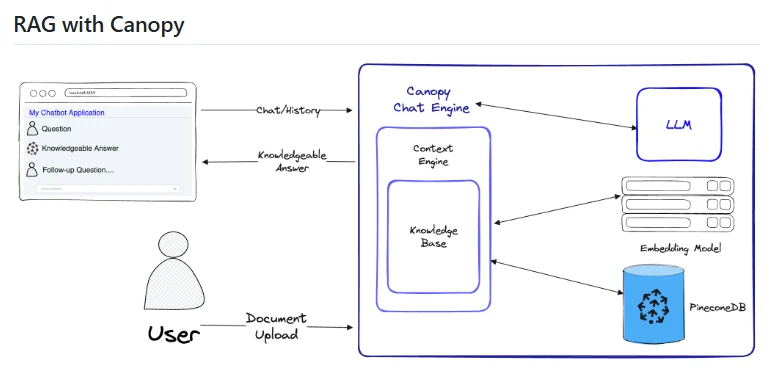
Canopy 的出现旨在降低构建复杂 RAG 管道的门槛,提供一套模块化、易于使用的组件和工具,使得开发者可以更快速、更高效地构建出高质量的 RAG 应用。作为 Pinecone 的开源项目,Canopy 自然地与 Pinecone 的向量数据库无缝集成,但也支持与其他向量存储和数据源的连接。无论是构建智能问答系统、文档摘要工具、还是需要利用外部知识进行内容创作的应用,Canopy 都提供了一个灵活且强大的平台。其核心目标是让开发者能够专注于应用的核心逻辑,而无需花费过多精力在 RAG 管道的底层实现和集成细节上。通过 Canopy,开发者可以更轻松地将最先进的 RAG 技术应用于各种实际场景,从而提升 LLMs 的性能和实用性。
Canopy 的功能
Canopy 框架提供了一系列关键功能,以简化和增强检索增强生成应用程序的开发:
- 模块化组件: Canopy 提供了一系列预构建的模块化组件,例如文档加载器、文本分割器、嵌入模型接口、检索器和生成器。这些组件可以灵活地组合和配置,以构建各种不同的 RAG 管道。
- 与 Pinecone 的深度集成: 作为 Pinecone 的官方开源项目,Canopy 与 Pinecone 向量数据库实现了深度集成,可以轻松地使用 Pinecone 进行高效的文档检索。
- 灵活的检索器支持: 除了 Pinecone 之外,Canopy 还支持集成其他类型的检索器,例如基于传统索引的检索方法或者与其他向量数据库的连接。
- 可定制的生成流程: 开发者可以根据自己的需求选择和配置不同的 LLMs 作为生成器,并可以定制生成过程中的参数和策略。
- 易于扩展的架构: Canopy 的架构设计考虑了可扩展性,开发者可以轻松地添加自定义的组件,例如自定义的文档加载器、文本分割器或者检索器,以满足特定的需求。
- 端到端的 RAG 管道示例: Canopy 提供了清晰的示例代码和教程,展示了如何使用其组件构建完整的端到端 RAG 管道,帮助开发者快速上手。
- 支持多种数据源: Canopy 能够处理来自不同数据源的文档,例如本地文件、Web 页面、数据库等,为构建多样化的 RAG 应用提供了便利。
- 关注性能和效率: 虽然 Canopy 的主要目标是简化开发,但它也注重性能和效率,尤其是在与 Pinecone 向量数据库结合使用时,可以实现快速的文档检索和生成。
如何使用/快速开始
要开始使用 Canopy 框架构建您的 RAG 应用程序,您可以按照以下步骤进行操作:
- 安装 Canopy: 首先,您需要安装 Canopy 库。可以使用 pip 命令进行安装:
pip install pinecone-canopy - 准备您的知识库: 准备您想要用于检索的文档数据。这可以是一个包含文本文件的目录、一个数据库,或者任何其他形式的文档集合。
- 配置 Pinecone (如果需要): 如果您计划使用 Pinecone 作为您的向量数据库,您需要设置您的 Pinecone API 密钥和环境。
- 加载和预处理文档: 使用 Canopy 提供的文档加载器加载您的文档数据,并使用文本分割器将文档分割成更小的块。
- 创建文档嵌入: 使用 Canopy 提供的嵌入模型接口(例如 OpenAIEmbeddings)将文档块转换为向量嵌入。
- 创建和配置检索器: 根据您的需求选择和配置一个检索器。如果您使用 Pinecone,您需要创建一个 Pinecone 索引并将文档嵌入上传到该索引。
- 选择和配置生成器: 选择您想要使用的 LLM 作为生成器,并配置相应的 API 密钥(例如 OpenAI 的 API 密钥)。
- 构建 RAG 管道: 使用 Canopy 提供的工具将加载器、分割器、嵌入模型、检索器和生成器连接在一起,构建您的 RAG 管道。
- 测试您的 RAG 应用程序: 输入一些查询或问题,测试您的 RAG 应用程序是否能够正确地检索相关信息并生成高质量的答案或文本。
以下是一个简化的示例代码片段,展示了如何使用 Canopy 框架构建一个基本的 RAG 管道(需要您已经安装了必要的库并设置了相关的 API 密钥):
from canopy.context_engine.models import OpenAIEmbeddingModel
from canopy.context_engine.pipeline import ContextEnginePipeline
from canopy.llm import OpenAILLM
from canopy.models import Document
from canopy.retriever import PineconeRetriever # 或者其他您选择的检索器
# 假设您已经有了您的文档数据
documents = [Document(id="doc1", content="文档1的内容"), Document(id="doc2", content="文档2的内容")]
# 初始化嵌入模型和 LLM
embedding_model = OpenAIEmbeddingModel()
llm = OpenAILLM()
# 初始化检索器 (这里以 Pinecone 为例,您需要配置您的 Pinecone 连接)
retriever = PineconeRetriever(index_name="your_index_name")
# 构建 ContextEnginePipeline
pipeline = ContextEnginePipeline(
embedding_model=embedding_model,
retriever=retriever,
llm=llm
)
# 输入查询
query = "您的查询内容"
# 获取 RAG 的输出
response = pipeline.query(query, documents=documents)
# 打印结果
print(response)
请务必查阅 Canopy 的 GitHub 仓库 以获取最准确和最新的使用方法、API 文档和示例代码,以便更深入地了解如何使用 Canopy 构建您自己的强大的 RAG 应用程序。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/canopy.html -APPMARK
MedRAG 是一个专为医疗领域设计的检索增强生成框架,通过整合诊断知识图谱和电子健康记录检索,利用大型语言模型的生成能力,旨在提高医疗诊断和治疗建议的准确性和可靠性,从而为医疗从业人员提供更精准的决策支持。