

什么是 STORM
STORM 是一个由 LLM(大型语言模型)驱动的知识管理系统,旨在通过互联网研究主题并生成带有引用的完整报告。STORM 的目标是自动化研究过程,并生成维基百科风格的文章。
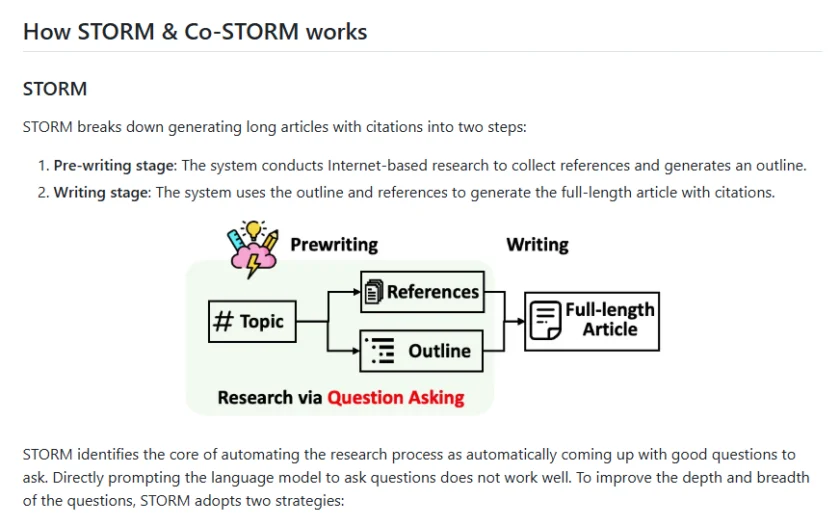
STORM 通过将文章生成过程分解为两个主要步骤来实现这一点:预写阶段和写作阶段。
- 预写阶段: 系统进行基于互联网的研究,以收集参考文献并生成文章大纲。
- 写作阶段: 系统使用生成的大纲和参考文献来生成带有引用的完整文章。
STORM 旨在解决自动提出好问题的核心问题。为了提高问题的深度和广度,STORM 采用了两种策略:
- 视角引导的问题提问: 给定输入主题,STORM 通过调查来自类似主题的现有文章来发现不同的视角,并使用它们来控制问题提问过程。
- 模拟对话: STORM 模拟维基百科作者和基于互联网资源的专家之间的对话,以使语言模型能够更新其对主题的理解并提出后续问题。
STORM 支持人机协作的知识管理,以支持更符合需求的信息搜寻和知识管理。
STORM 的功能
STORM 具有以下主要功能:
- 自动生成文章大纲: 通过查询类似主题的文章,STORM 能够生成详细的文章大纲,从而提高文章的覆盖面和组织性。
- 多视角信息整合: STORM 模拟多视角、基于搜索的对话,有助于增加参考文献的数量和信息的密度,从而生成更全面和有深度的报告。
- 互联网研究: STORM 能够进行互联网搜索,收集相关信息和参考文献,为文章的生成提供基础。
- 知识管理: STORM 不仅可以生成文章,还可以用于知识的组织和管理,帮助用户更好地理解和利用信息。
- 可定制性: STORM 提供了 API,支持定制不同的语言模型和检索/搜索集成,用户可以根据自己的需求进行配置。
- 人机协作: Co-STORM 进一步增强了其功能,支持人机协作,以实现更符合需求和偏好的信息搜寻和知识管理。
如何使用/快速开始
要开始使用 STORM,您可以按照以下步骤操作:
- 安装 knowledge-storm 库: 使用 pip 命令安装 knowledge-storm 库:
pip install knowledge-storm - 克隆 GitHub 仓库(可选): 如果您想直接修改 STORM 引擎的行为,可以克隆 GitHub 仓库:
git clone https://github.com/stanford-oval/storm.git cd storm - 使用 You.com 搜索引擎和 OpenAI 模型: 以下是一个使用 You.com 搜索引擎和 OpenAI 模型的示例:
from storm_wiki import STORMWikiRunner runner = STORMWikiRunner( llm_name="gpt-3.5-turbo", embedding_llm_name="text-embedding-ada-002", search_engine="you.com", ) article = runner.run("Your Topic") print(article) - 配置语言模型和搜索引擎: 您可以根据需要配置不同的语言模型和搜索引擎。STORM 支持多种语言模型和搜索引擎的集成。
- 运行 STORM 引擎: 使用
STORMWikiRunner类来运行 STORM 引擎,并指定您想要研究的主题。
通过这些步骤,您可以快速开始使用 STORM 来生成高质量的维基百科风格的文章。
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/storm.html -APPMARK
Canopy 是由 Pinecone 开发的开源框架,旨在简化构建检索增强生成(RAG)应用程序的过程。