

摘要:Pinecone 是一款面向 RAG、语义搜索和 Agent memory 场景的向量数据库平台。它并不直接生成内容,而是负责把文本、文档、图像嵌入后的向量高效存储、索引和检索出来,从而让上层大模型在需要时拿到相关上下文。对 AI 导航站读者来说,Pinecone 的价值在于:如果你要把大模型真正接进生产系统,向量检索层往往比聊天界面更关键,而 Pinecone 就是这一层的代表性产品。
这是什么产品
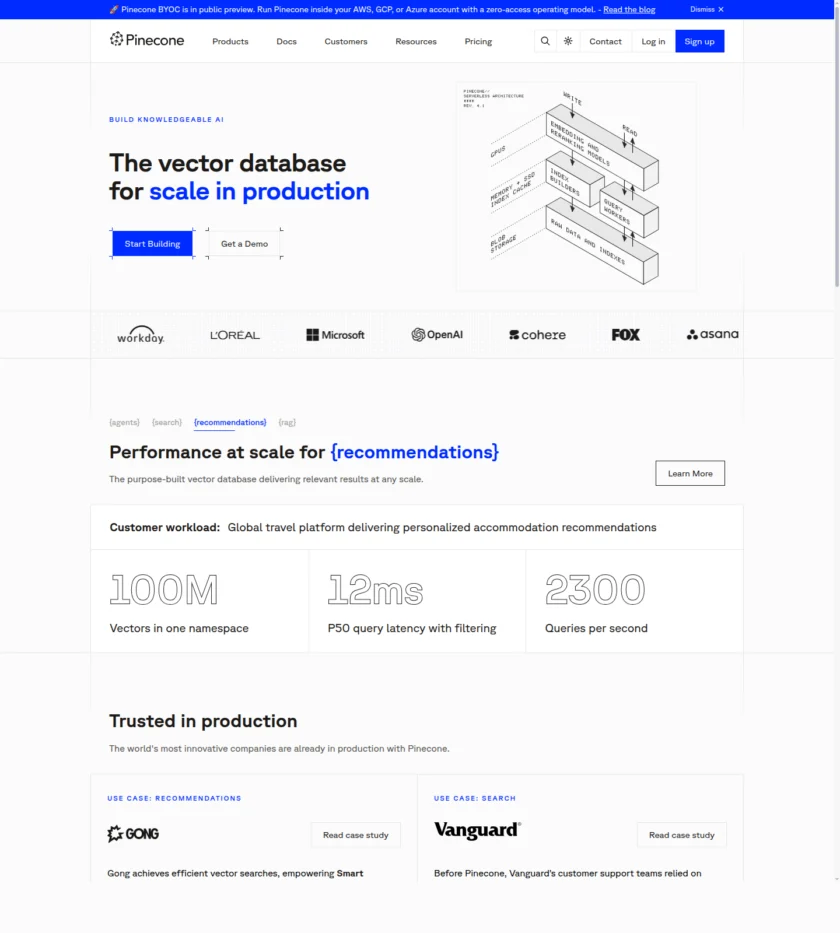
Pinecone 官网首页的标题非常直接:The vector database to build knowledgeable AI。这里的关键词不是 chatbot、assistant 或 content generation,而是 vector database 和 knowledgeable AI。它说明 Pinecone 的定位是知识检索基础设施,而不是终端生成产品。对于 RAG 系统来说,生成模型只负责“说”,而 Pinecone 这种向量数据库负责“找”,也就是在海量数据里找到最相关的上下文,再把结果送给模型。
从产品类别上看,Pinecone 适合被放进 AI 知识库 / RAG 相关分类,而不是简单归入 AI 聊天或 AI 开发工具泛类。原因是它解决的是检索问题:如何在毫秒级时间内从数百万到数十亿级向量中找到语义相近结果,如何构建索引、做 metadata 过滤、做混合检索、支撑 agent memory 和知识问答。对于很多团队来说,这一层决定了 RAG 最终是否可用。
官网描述里反复强调 search through billions of items in milliseconds,这说明 Pinecone 的核心不是实验性 demo,而是生产级检索性能。对技术团队而言,选择 Pinecone 不是因为它“更炫”,而是因为向量数据库一旦进入业务核心链路,就必须考虑延迟、扩展性、托管体验和运维复杂度。Pinecone 试图把这些底层问题尽量封装掉,让开发者更专注于应用层。
核心功能与使用体验
Pinecone 的核心能力首先是向量存储与相似度检索。开发者把文本、段落、FAQ、工单、商品、代码片段或其他对象转换成 embedding 后,可以写入 Pinecone,再通过相似度搜索找出最相关结果。这一步是 RAG 的核心,因为模型回答质量很大程度取决于你能不能先找准上下文。
第二个关键能力是托管式索引与扩展。很多团队并不想自己维护底层向量库集群、索引结构、扩容策略和查询优化,尤其当数据量变大后,这些工作会显著增加工程复杂度。Pinecone 的产品吸引力就在于把向量检索以平台服务形式提供出来,让开发者更多通过 API 和配置来完成工作,而不是自己从零构建整套基础设施。
第三个能力是为 AI 场景服务的周边特性。虽然公开首页和文档不会把所有细节都浓缩成一句话,但从其产品定位和 quickstart 组织方式可以看出,Pinecone 不是通用数据库简单改名,而是围绕 semantic search、RAG 与 AI assistant 这些场景组织文档和上手流程。对使用者来说,体验上的关键不是有没有图形界面,而是索引创建、数据写入、查询调用和上层框架集成是否足够顺手。
第四个实际价值是生态兼容性。Pinecone 常常作为上层 LLM 应用中的一环,与 embedding 模型、检索逻辑和生成模型配合工作。你可以把它看作“知识检索中台”:上游负责切分与嵌入,下游负责生成回答,中间由 Pinecone 承接检索任务。这也是它在 RAG 场景中被频繁提及的原因。
如何开始使用
Pinecone Quickstart 页面给出的上手路线比较友好。官方明确写到可以 manually、with AI assistance 或 with no-code tools 开始,这说明它希望覆盖不同类型开发者和团队,而不仅是熟悉底层数据库概念的人。对第一次接触向量数据库的用户来说,这是好事,因为它降低了从概念到第一次跑通检索链路的门槛。
一个典型的开始流程通常包括:注册账号、创建索引、准备 embeddings、写入向量数据、再通过查询接口做相似度搜索。随后,开发者再把搜索结果拼进提示词或 agent 的 memory 流程中,形成 RAG 或语义检索应用。与聊天产品不同,Pinecone 的“上手成功”不是看到一个漂亮对话框,而是成功完成一次写入和一次高相关度检索。
如果你是做知识库问答、企业搜索、文档助手或 agent memory,最合理的试用方式不是空跑 benchmark,而是拿自己的真实数据集测试。比如选 50 到 500 条 FAQ、文档段落或产品说明,把它们向量化后放进 Pinecone,再看检索结果是否足够稳定和相关。这样更能判断它是否适合你的应用,而不是只看概念介绍。
价格、开源与部署方式
从官网和 pricing 页看,Pinecone 的主形态是托管式云平台,而不是以开源自托管为主的向量数据库项目。也就是说,它更像“数据库即服务”,开发者通过官方平台创建和使用索引,再按资源与使用情况计费。这种模式的优点是上手快、运维负担低,缺点则是更多依赖官方托管能力。
价格页说明 Pinecone 已经形成正式商业化产品,而不是只提供社区试玩版。对采购或生产使用者来说,真正需要关心的是资源规模、请求量、延迟需求和部署区域,而不是只看“有没有免费入口”。向量数据库一旦进入线上链路,整体成本会和数据量、查询频率与检索策略一起变化,因此 Pinecone 更适合按业务负载来评估,而不是只拿轻量聊天工具的思路衡量。
在开源与部署方式上,当前公开页面更强调其官方平台能力,而不是把自己定位成可自由本地部署的开源产品。如果团队有强私有化要求,应该在正式选型前继续核实企业方案与合规选项。
适合哪些人和场景
Pinecone 最适合的是已经明确知道自己需要“检索层”的团队。比如企业知识库问答、客服助手、文档问答、代码搜索、推荐系统、Agent memory、语义相似匹配、多模态检索,这些都需要一个能稳定存储和查询向量的底层系统。对这类场景来说,Pinecone 的价值远大于终端表面交互,因为检索命中率直接决定上层回答质量。
对于创业团队和独立开发者,Pinecone 也适合快速做 RAG 原型。你不需要先组建数据库基础设施团队,就可以先把核心检索流程跑起来。对中大型团队来说,它则更像一个现成的检索中台,帮助团队在较短时间内把 AI 知识检索能力投入生产。
优势与限制
Pinecone 的最大优势是专注。它不试图成为“什么都能做”的平台,而是聚焦在向量检索这一层,把性能、托管体验和 AI 场景适配作为核心卖点。第二个优势是上手路径清晰,Quickstart 与定价信息公开,便于技术团队快速评估。第三个优势是适合生产环境,不只是实验性项目。
限制也很清楚。第一,Pinecone 自己不生成答案,它必须与 embedding 模型和上层生成模型搭配使用;所以如果用户期待的是“开箱即用聊天机器人”,它并不是那个产品。第二,托管平台虽然省运维,但也意味着你需要评估长期成本、供应商依赖和部署边界。第三,RAG 成败不仅取决于数据库本身,还取决于切分、嵌入模型、过滤策略和召回设计,因此 Pinecone 再强,也不能单独解决整个知识问答系统的所有问题。
对比与选择建议
如果把 Pinecone 和通用数据库方案相比,它的优势在于更聚焦向量检索和 AI 场景;如果和一些开源向量数据库相比,它的优势通常体现在托管与上手效率,而不是完全控制权。是否选择 Pinecone,取决于你更看重省运维、快速上线,还是更看重自托管与底层可控性。
我的建议是:如果你正在做生产级 RAG 或企业知识检索,且希望尽快获得稳定可用的托管检索层,Pinecone 值得优先测试;如果你更偏向自建基础设施或极度重视本地部署,再去比较其他开源向量库会更合理。
结论
Pinecone 值得被收录到 AI 知识库 / RAG 分类,因为它代表了大模型应用中非常关键但经常被忽视的一层:检索基础设施。对于想做知识型 AI、语义搜索和 Agent memory 的开发者与团队,它是非常值得优先了解和试用的工具。第一次打开官网时,最该先看的通常是首页定位、Quickstart 文档和 pricing 页面,再结合自己的数据规模决定是否适合进入正式选型。
官方来源
- Homepage: https://www.pinecone.io/
- Docs or quick start: https://docs.pinecone.io/guides/get-started/quickstart
- Release or distribution: https://docs.pinecone.io/guides/get-started/quickstart
- Pricing or licensing: https://www.pinecone.io/pricing/
本文采用 CC BY-NC 4.0 许可协议。商业转载、引用请联系本站获得授权,非商业转载、引用须注明出处。
链接:https://appmark.cn/sites/pinecone.html -APPMARK
LLM-App 是一个由 Pathway.com 开发的开源框架,用于构建实时的、由大型语言模型(LLMs)驱动的知识库应用程序。